Pillar Hub
Agentic AI Architecture
Production patterns for building AI agent systems that survive real enterprise constraints: governance requirements, latency SLAs, data classification boundaries, cost controls, and human-in-the-loop obligations. Not demos — deployed systems.
What Agentic AI Architecture Actually Means
The term "agentic AI" has been diluted by marketing to mean almost any LLM with a tool call. That is not what production agentic AI architecture means.
A production AI agent is a system that can observe state, maintain a world model, plan multi-step actions, execute tool calls, handle failure and uncertainty, and make consequential decisions — repeatedly, at scale, within defined governance constraints. The architectural decisions that matter are not which LLM framework you use. They are how the agent maintains accurate situational awareness, how it gates irreversible decisions, how it handles contradictions between its beliefs and new observations, and how every decision is logged with enough fidelity to reconstruct the reasoning chain.
Most agent implementations in production fail at the orientation layer — the agent's model of the current state. An agent that has accumulated stale context, hallucinated a prior step's outcome, or silently incorporated a contradictory observation will reason correctly within its (wrong) world model and arrive at a wrong answer every time. The architecture patterns on this page are designed to prevent that class of failure, not just the surface-level failures that show up in benchmarks.
Core Architecture Patterns
Six production patterns, each with implementation detail and failure mode documentation.
OODA Loop Agent Runtime
Observe–Orient–Decide–Act as a first-class architecture. Explicit world model, contradiction detection, risk-gated decisions.
Multi-Agent Orchestration
Supervisor patterns, hierarchical delegation, event-driven coordination. When to split agents and when to keep them together.
Multi-LLM Routing
Route by task type, data classification, latency budget, and cost. The SmartCIO pattern for resilient, cost-controlled inference.
MCP Server Integration
Model Context Protocol as the enterprise tool integration standard. Governed, composable, provider-agnostic.
Agent Governance Controls
Human-in-the-loop architecture, risk budgets, audit trails. Making agents auditable under SR 26-2 and enterprise risk frameworks.
Context & Memory Architecture
RAG at agent scale, semantic caching, working memory vs long-term memory. The context compilation layer agents need to survive production.
The Three Agent Architecture Questions
1 What is the agent's decision loop?
Most agent frameworks default to ReAct (Reasoning + Acting): the agent generates a thought, selects a tool, observes the result, generates another thought, and repeats. ReAct is simple, well-understood, and adequate for straightforward retrieval-and-answer tasks.
For complex enterprise workflows — multi-step analysis, high-stakes decision support, workflows with adversarial or noisy inputs — the OODA loop is a better decision architecture. The key difference is that OODA treats orientation (the agent's world model) as a first-class, explicitly maintained component rather than an implicit by-product of the chain-of-thought. This makes the agent's beliefs inspectable, correctable, and auditable — which matters enormously when the agent's decisions have regulatory or financial consequences.
The practical question is: does your agent need to maintain coherent state across 10+ tool calls, handle contradictory observations gracefully, and produce an audit trail that reconstructs its reasoning? If yes, the OODA architecture is worth the additional complexity. If no, ReAct is fine.
2 Single agent or multi-agent?
The instinct in enterprise AI projects is to build one general-purpose agent that can do everything. This is the wrong instinct for most production use cases.
Single-agent architectures are appropriate when the task is coherent — a single domain of expertise, a consistent set of tools, a bounded decision space. The agent's context stays manageable, its reasoning is coherent, and failures are localized.
Multi-agent architectures are appropriate when the task genuinely requires specialist capabilities that cannot coexist in a single context window without degrading each other. An AML investigation pipeline that needs a document retrieval specialist, a transaction pattern analyst, a regulatory knowledge retriever, and a report drafting agent is a genuine multi-agent problem — each specialist has a different tool set, different knowledge base, and different failure mode profile.
The failure mode of premature multi-agent architecture is coordination overhead and debuggability collapse: when something goes wrong in a five-agent pipeline, finding the root cause requires tracing across five separate reasoning chains. Build the simplest agent that solves the problem, then split when you have specific evidence that a single agent is hitting a capability ceiling.
3 Where does human oversight sit?
This is the question that enterprise AI teams most frequently get wrong — not because they don't want human oversight, but because they implement it incorrectly.
Advisory oversight (the agent can proceed if a human doesn't review within N minutes) is not oversight. It is a paper trail. Under load, when queues back up, the agent proceeds without review, the "oversight" never happened, and you have documented that you built a system with nominal oversight and real autonomy.
Structural oversight (the agent physically cannot take the irreversible action without a human approval token) is real oversight. It creates queues when reviewers are unavailable. It creates operational pressure to hire and train enough reviewers. It creates the friction that tells you the governance is actually working.
The architectural rule is: every irreversible action (filing, transaction, decision that becomes system-of-record) requires a structural human gate. Every reversible action (routing, classification, draft generation) can be monitored with post-hoc audit rather than synchronous approval. The boundary between reversible and irreversible is a governance decision, not a technical one — and it needs to be made explicitly, documented, and defended to auditors.
Agent Architecture Decision Framework
Use this to select the right architecture before writing code.
Does the task require multiple steps with conditional branching?
→ Single-agent with OODA loop or ReAct
If no branching, just call the LLM directly — no agent needed.
Do different steps require fundamentally different capabilities?
→ Multi-agent with supervisor
E.g., a retrieval specialist + a reasoning specialist + a code executor.
Does the workflow involve irreversible actions (filing, transactions)?
→ Human-gated OODA agent
Irreversible actions require a structural human approval gate, not a soft advisory.
Is the workload high-volume and homogeneous?
→ Parallel agent fleet with central registry
AML triage, document classification — fan out with agent registry for governance.
Does the task span multiple external systems with different latencies?
→ Event-driven multi-agent with async tool calls
Avoid synchronous chains when one slow tool holds up the whole pipeline.
Production Failure Modes
Orientation Drift
The agent's world model diverges from actual state as it processes contradictory observations. Symptoms: circular reasoning, incorrect assumptions about prior steps, confident wrong answers.
Fix: Explicit contradiction detection in the Orient phase. Log world model at each step.
Tool Call Explosion
Agent makes 40+ tool calls on a task that should require 8. Usually caused by a miscalibrated stop condition or an agent that retries ambiguous results.
Fix: Hard step limit with escalation on hit. Monitor tool call count per task as a metric.
Silent Governance Bypass
Human-in-the-loop gates that are advisory rather than structural. Under load, agents proceed without review. Discovered during audit, not during development.
Fix: Structural approval tokens, not timeouts. If the token is absent, the action does not execute.
Context Window Overflow
Long-running agents accumulate context until they exceed the model's window. Behavior degrades silently — no error, just increasingly incoherent reasoning.
Fix: Explicit world model compression at regular intervals. Track context token count as a metric.
Stale Tool Schema
External APIs change their response format. Agent is trained on a prior schema, receives new format, misparses silently, and propagates wrong data downstream.
Fix: Tool response validation with schema versioning. Alert on unexpected response structure.
Cost Runaway
An agent loop that doesn't terminate correctly keeps calling expensive models until it hits a credit limit. Can consume a month's budget in hours.
Fix: Per-task cost budget enforced at the router level. Circuit breaker at daily/hourly cost thresholds.
The Governance Requirement Is an Architecture Requirement
In enterprise environments — especially regulated industries — AI agent governance is not a layer you add after the architecture is done. It is an architecture requirement that shapes every other design decision.
The governance requirements for production agentic AI include: a complete audit trail of every tool call and decision, prompt version tracking so you can reproduce any past behavior, explicit human oversight architecture for material decisions, model version control with change management, and output distribution monitoring that surfaces behavioral drift before it causes incidents at scale.
None of these can be retrofitted cleanly into an agent architecture that wasn't designed for them. The logging hooks, the approval gates, the version tracking, the cost accounting — they all need to be in the foundational architecture, not bolted on after a compliance review.
The patterns on this page are designed with governance as a first-class constraint, not an afterthought. The architectures that survive in regulated enterprises are the ones that treat governance instrumentation as part of the design, not evidence of regulatory pressure.
Featured: Deep Dives
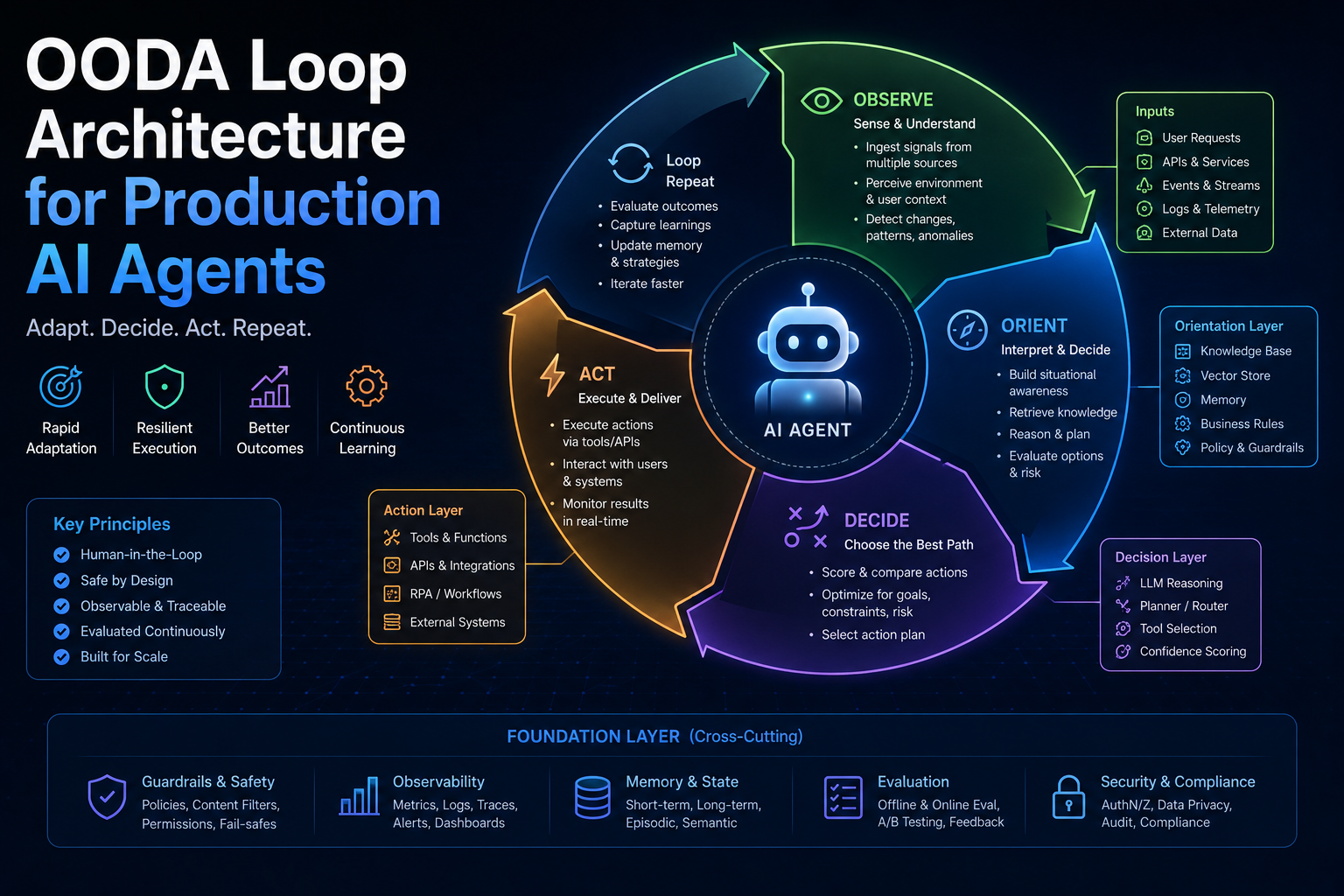
OODA Loop Architecture for Production AI Agents
John Boyd designed the OODA loop for fighter pilots making life-or-death decisions in milliseconds with incomplete information. It turns out this is a better mental model for production AI agents than the ReAct loop — especially in high-stakes, time-pressured environments where agents need to fail fast, course-correct, and maintain situational awareness across a multi-step decision horizon.

The 85% Problem: Agentic AI Has Outrun the Data Infrastructure It Needs to Survive Production
Fivetran's 2026 Agentic AI Readiness Index reveals that 85% of enterprises are running agent workloads on data foundations that aren't ready — and in banking, where finance teams grew agentic AI adoption 600% year-over-year, the gap between deployment and data readiness is now a model risk surface.

Five AI Vendors Shipped Agent Registries in One Quarter — That's Not Competition, It's a Production Crisis Signal
When Microsoft, AWS, Google, ServiceNow, and Okta all ship 'agent registries' within weeks of each other, enterprise architects need to read that convergence carefully — because the agent inventory problem is now a compliance deadline, not a backlog item.
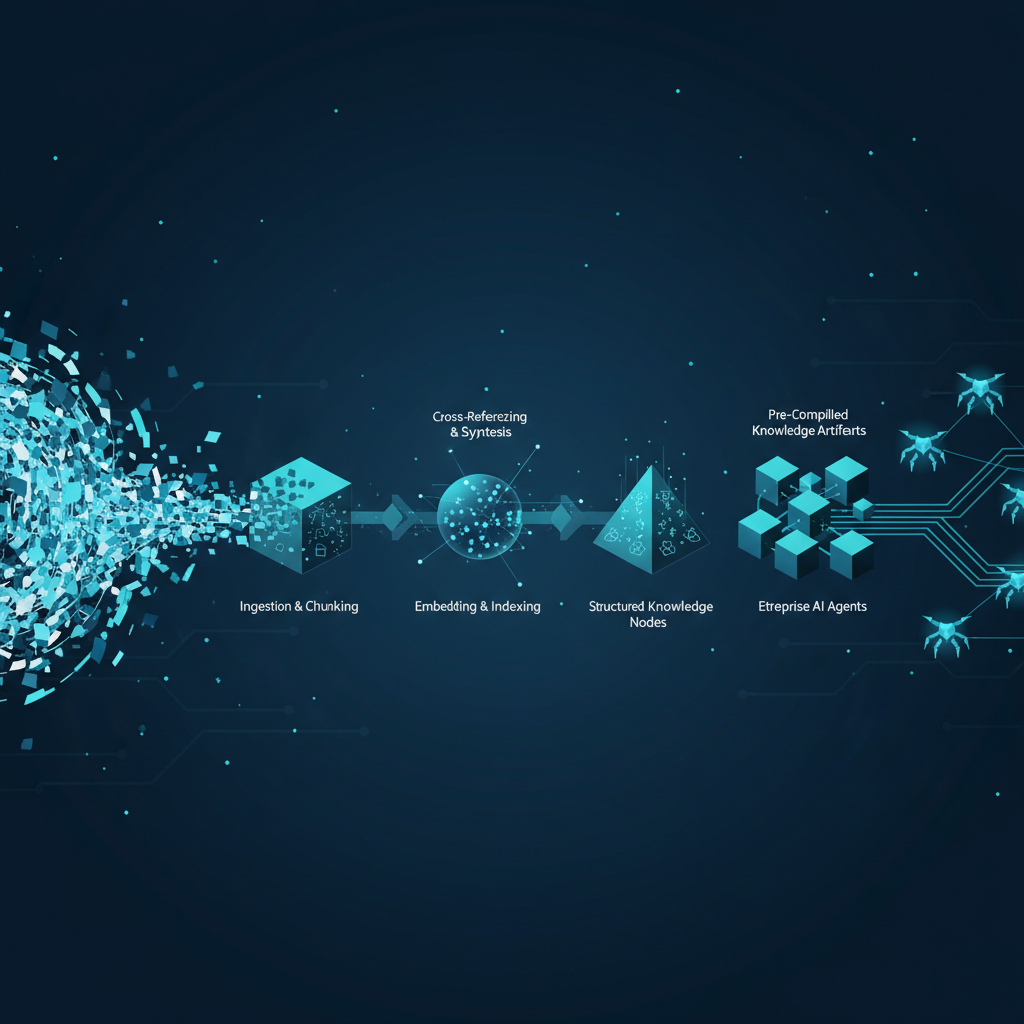
Pinecone Nexus and Context Compilation: RAG at Agent Scale
Pinecone's pivot from vector database to 'knowledge engine' exposes a structural flaw in how enterprise teams built their RAG stacks — and signals a new architecture layer between raw data and agent runtime that will reshape how production AI systems are designed.

Human-Led, AI-Accelerated: Why the Winning Stack in 2026 Isn't Fully Autonomous
Gartner expects 40% of agentic-AI projects to be cancelled by 2027. Production failure rates hover near 25%. Yet 'human-led, AI-accelerated' teams keep quietly outperforming both pure-human and fully-autonomous setups. The pattern is now too consistent to ignore.
Agent Stack Update April 2026: Opus 4.7 and MCP Standardization
Anthropic ships a new flagship, the Model Context Protocol crosses 97 million installs and exits Anthropic's control, and Oracle lines up $50B to build the physical plant beneath it all. This week, AI agents stopped being a demo and started looking like infrastructure.
More in Agentic AI Architecture (12 posts)
Attribute Knowledge RAG Pattern for LLM Governed Attributes
Jul 6, 2026
FDA Has No Framework for Agentic Clinical AI. ARPA-H Is About to Create One.
Jun 23, 2026
Cursor Is Now SpaceX: Enterprise Agentic Coding's New Lock-In Risk
Jun 18, 2026
OpenAI's Pre-Release Safety Trick: Make Models Think They're in Production
Jun 17, 2026
The FSB Said the Quiet Part Loud: AI Must Now Govern AI in Banks
Jun 16, 2026
The Agentic AI Governance Framework Every Enterprise Needs Now
Jun 12, 2026
Thompson Sampling for Personalization: A Hands-On Tutorial
Jun 12, 2026
Bank AI Agents Have No Kill Switch — and the Data Proves It
Jun 11, 2026
REA Framework & Bank Ontology: A Complete Tutorial
Jun 11, 2026
Vector Database Comparison for RAG 2026: Pinecone vs ChromaDB vs Redis vs Weaviate
Jun 10, 2026
LangChain vs LangGraph 2026: Which to Use for Enterprise Agents
Jun 9, 2026
Fintech AI Architecture Patterns 2026: A Production Pattern Library for Regulated Financial Services
Jun 8, 2026
Structured Learning
Want hands-on agentic AI courses?
SuperML.org has structured learning tracks for NL2SQL Agents, Agentic RAG, and Enterprise AI Architecture — with code labs and production templates.
Related Topic Hubs