SR 11-7 Model Risk for AI Systems: What Banks Actually Need to Build
SR 11-7 is 15 years old and SR 26-2 explicitly excluded generative AI from its scope. Banks are now governing their most powerful AI systems against a framework that was never designed for them. Here's the practitioner guide to what model risk management actually looks like when you apply it to LLMs, RAG pipelines, and agentic AI.


Table of Contents
There is a specific kind of regulatory risk that doesn’t appear in exam findings until it’s too late: the gap between what a framework was designed to govern and what your institution is actually deploying.
SR 11-7 — the Federal Reserve’s 2011 Supervisory Guidance on Model Risk Management — was designed to govern the quantitative models that banks use for credit risk, market risk, and capital adequacy. Logistic regression scorecards. VaR models. Monte Carlo simulations. Models where “input → transformation → output” maps cleanly onto a defined feature set, a bounded output space, and a back-testable performance metric.
SR 26-2, published April 17, 2026, replaced SR 11-7 with updated guidance — and explicitly excluded generative AI and agentic AI from scope. The gap is now official. Banks are deploying LLMs in credit underwriting, agentic systems in AML triage, RAG pipelines in compliance research — and every one of those deployments exists in a governance vacuum that neither the old framework nor the new one was designed to fill.
This post is the practitioner’s guide to closing that gap. Not the theory — you have regulators, consultants, and vendors for that. The architecture: what model risk management actually requires, why the existing instruments fail for AI, and what you need to build to govern LLMs and agents in a way that will survive contact with examiners.
What SR 11-7 Actually Required (And Why It Mattered)
Before you can understand the gap, you need to understand what SR 11-7 actually built. The framework had three pillars that worked together as a coherent system.
Pillar 1: Model Development and Implementation. SR 11-7 required that models be developed with documented assumptions, a defined scope of use, data quality controls, and a process for evaluating conceptual soundness. The key word is conceptual soundness — the idea that you can reason from first principles about why the model should work, test whether it does work, and identify the conditions under which it fails.
For a logistic regression credit model, this is tractable. You have feature coefficients you can interpret. You can challenge whether age-of-oldest-account is a valid predictor and why. You can stress-test the model against recession scenarios and document how it behaves. The conceptual soundness review is hard work, but it’s bounded work.
For a fine-tuned LLM doing credit memo analysis, you have none of those instruments. The “model” is a multi-billion-parameter transformer trained on data you didn’t select, haven’t audited, and cannot fully characterize. Its behavior in distribution is observable. Its behavior out of distribution — which is exactly when risk materializes — is not predictable from first principles. Conceptual soundness review is not meaningful for a system where the concepts are embedded in weights that no analyst can read.
Pillar 2: Model Validation. SR 11-7 required independent validation: a separate function that challenges model assumptions, evaluates performance on out-of-sample data, and produces a formal opinion on model risk. Validators were expected to replicate model development, back-test against historical outcomes, and stress-test under adverse conditions.
The instruments are back-testing, benchmarking, sensitivity analysis, and outcomes analysis — all of which require either a ground truth you can compare against or a defined metric space you can measure within.
For LLM outputs, ground truth is the problem. When an LLM drafts a Suspicious Activity Report narrative, the ground truth is “what a skilled compliance analyst would have written,” which is not a fixed value you can back-test against. When a RAG pipeline retrieves regulatory context to answer a compliance question, the ground truth is “the correct interpretation of the regulation,” which often doesn’t exist as a labeled dataset. Validation at the output level requires judgment, which means it cannot be automated at the scale most banks need.
Pillar 3: Governance and Controls. SR 11-7 required a model inventory, a model risk appetite framework, ongoing performance monitoring, and escalation procedures for model failures. In practice, this meant model risk committees, model risk ratings, and periodic model review cycles.
The governance infrastructure is the most transferable pillar — and even here, the instruments break down. A model inventory requires you to define what counts as a “model.” Under SR 11-7, a model had clear characteristics: it took quantitative inputs and produced quantitative outputs using a defined mathematical transformation. An LLM used as a tool by an AI agent — does that count as a model under inventory? Does each prompt template version count as a model change requiring review? Does a RAG system’s retrieval component require separate inventory from its generation component? These questions don’t have settled answers under existing frameworks.
Why SR 26-2 Made the Gap Official
On April 17, 2026, the OCC, FDIC, and Federal Reserve jointly issued revised model risk management guidance under SR 26-2. The update addressed several legitimate gaps in SR 11-7 — particularly around third-party models, model complexity, and explainability — but it made one decision that matters more than any of the updates: it explicitly carved generative AI and agentic AI out of scope, noting that additional guidance for these systems would come separately.
Read that carefully. The principal banking regulators updated their foundational model risk framework for the first time since 2011 — and chose not to address the most consequential AI systems banks are currently deploying. This was not an oversight. Federal Reserve Vice Chair Michelle Bowman confirmed in a May 2026 speech that the revised guidance “applies only narrowly to traditional models and basic AI applications” and does not extend to generative or agentic AI.
The regulatory message is: we know the gap exists, we know it’s important, and we’re not ready to prescribe requirements for it yet. The operational message for banks is: you are now governing your riskiest AI systems against a framework that doesn’t apply to them, with examiners who don’t yet have a consistent standard to apply.
That is not a comfortable position, but it is an honest one. The banks that treat this as permission to skip governance will accumulate supervisory liability. The banks that treat it as an opportunity to build governance that actually works — before the requirements are prescribed — will have a structural advantage.
The Four Governance Instruments Banks Actually Need
Here is what model risk management for LLMs and agentic AI requires in practice, based on production deployments in regulated financial services environments.
1. Prompt Versioning and Change Management
In SR 11-7, a model change — even a minor parameter adjustment — required notification to the model risk function and, for material changes, a validation review before production deployment. The equivalent for LLMs is prompt versioning.
A prompt is not just a user interface decision. It is a specification of model behavior that directly determines output distribution. A prompt that includes “be conservative in ambiguous cases” produces different outputs than one that doesn’t. A system prompt that defines the model’s role as “compliance assistant” shapes responses differently than one that defines it as “document summarizer.” These are not UX choices. They are model behavior choices, and they require the same change management discipline as parameter changes in traditional models.
What this looks like in practice:
- Every system prompt in every production LLM deployment is versioned in a git repository or equivalent
- Prompt changes go through a review process that includes the model risk function for any LLM touching material financial decisions
- Rollback capability exists at the prompt level: if a prompt change produces unexpected output shifts, you can revert in minutes, not weeks
- A/B testing framework for prompt changes, with statistical monitoring of output distribution shifts across versions
The tooling for this exists: LangSmith, LangFuse, and comparable observability platforms support prompt versioning natively. The governance question is organizational: who owns the prompt change process, who has authority to approve, and what constitutes a material change requiring full validation review vs. a minor change requiring only monitoring.
2. Structured Output Logging for Audit Trails
SR 11-7 required that models maintain records sufficient to reconstruct model outputs and support examination. For a traditional credit model, this meant storing input features and output scores. For LLMs and agents, the requirement is more complex because the decision process spans multiple steps and involves non-deterministic generation.
A production-grade audit trail for an LLM deployment must capture:
- Input: the full prompt, including system prompt version, retrieved context (for RAG), and user query
- Output: the complete model response, not just the extracted structured fields
- Metadata: model name and version, temperature and sampling parameters, token counts, latency
- Downstream action: what happened as a result of the output — was it presented to a human, used to trigger a workflow, stored in a system of record?
For agentic systems, the audit trail must also capture the reasoning chain: which tools the agent called, in what order, with what inputs and outputs, and what decision logic drove each tool selection. An agent that queries a credit bureau, retrieves a regulatory document, and produces a lending recommendation needs a complete event log that allows you to reconstruct exactly what happened, even if the agent ran without real-time human monitoring.
Storage and cost reality: Comprehensive output logging for a high-volume LLM pipeline adds 8–15% to infrastructure costs at production scale. This is not optional overhead. It is the governance artifact. If you can’t produce it during an examination, you can’t defend the deployment. The cost calculation should compare audit storage costs against the cost of a consent order.
3. Human-in-the-Loop Architecture Mapped to Materiality
SR 11-7’s governance pillar required escalation procedures for model failures — but it assumed that a human was always in the loop at the point of consequential decision. Credit decisions required human review. Underwriting exceptions went to committees. The model was an input to a human decision process, not the decision process itself.
Agentic AI inverts this. An agent that runs autonomously through an AML case investigation, produces a risk rating, routes the case for review or closure, and generates a SAR narrative is making consequential decisions at machine speed, often without real-time human oversight. The governance question is not whether humans should be involved — they must be for material decisions — but where in the agentic workflow the human checkpoint needs to sit.
The design principle is materiality-gated oversight:
| Decision Type | Risk Level | Required Oversight |
|---|---|---|
| Routing / classification | Low — recoverable | Post-hoc audit within 24h |
| Draft document generation | Medium — human review before use | Synchronous approval gate |
| Case closure recommendation | High — regulatory consequence | Mandatory human approval |
| SAR filing recommendation | High — legal consequence | Senior compliance review + sign-off |
| Credit decision contribution | Material — fair lending risk | Full validation + human override capability |
The system architecture must make these checkpoints explicit and enforceable, not advisory. An agent that can bypass a human approval gate when latency is high will eventually do so under load. The control must be structural: if the human approval token is not present, the consequential action does not execute.
4. LLM-Specific Validation Procedures
The hardest problem in AI model risk management is validation. Traditional validation requires a ground truth — a set of known-correct outcomes you can compare model outputs against. For most LLM use cases in financial services, that ground truth either doesn’t exist or is expensive to create.
The validation approach for LLMs must adapt accordingly:
Red-teaming over back-testing. Traditional back-testing measures model performance against historical outcomes. For LLMs, adversarial red-teaming — structured attempts to elicit harmful, incorrect, or biased outputs — is more informative than historical comparison. Red-teaming should be systematic, documented, and conducted by a team independent of model development.
Output distribution monitoring over point accuracy. Rather than measuring whether each output is “correct,” monitor the statistical properties of output distributions over time. For a credit memo analysis LLM, monitor the distribution of sentiment scores, the frequency of specific risk flag categories, and the correlation between model outputs and eventual human reviewer decisions. Significant distributional shifts signal model behavior changes that warrant investigation.
Challenger models for conceptual soundness. Where ground truth is unavailable, challenger model comparison provides a weaker but still useful signal: if two models with different architectures produce systematically different outputs on the same inputs, one of them is wrong, and the disagreement itself is a risk signal worth documenting.
Bias and fairness testing. SR 11-7 required sensitivity analysis. For LLMs used in any customer-facing financial decision, the equivalent is systematic testing for differential output behavior across protected class proxies. This is not just a fair lending requirement — it is a model risk requirement. An LLM that produces different credit analysis outputs for inputs that differ only in ZIP code (a common proxy for race) has a systematic bias that constitutes model risk regardless of the legal exposure.
The Inventory Problem
Before any of the above is actionable, you need to know what you’re governing. The SR 11-7 model inventory was a tractable problem because “model” was a well-defined category. The AI equivalent is not.
A practical AI system inventory for a bank should capture:
- Foundation models: every third-party LLM or fine-tuned model in production (GPT-4o, Claude Sonnet, Llama 3, fine-tuned variants), with the vendor contract, access tier, and data-sharing terms
- RAG configurations: each RAG deployment as a distinct entry, including retrieval corpus, embedding model, chunk size and overlap, and retrieval parameters — because the retrieval configuration determines output as much as the generation model does
- Prompt templates: every system prompt in production, versioned and linked to the model entry it modifies
- Agentic workflows: each agent system as a distinct entry, with the tool set, memory architecture, orchestration pattern, and human oversight points documented
- Downstream system integrations: for each AI system, what systems does it write to, what processes does it trigger, and what human review steps exist before its outputs become system-of-record entries
This inventory is harder to maintain than a traditional model inventory because the components change faster. A new model version, a new tool in an agent’s toolkit, a changed retrieval corpus — each of these changes the effective behavior of the AI system in ways that may or may not require validation review. The inventory governance question is: who has authority to add items, who reviews changes, and what triggers a full validation cycle vs. a monitoring review?
What Examiners Will Actually Ask
The OCC, Federal Reserve, and FDIC are in the process of developing formal AI governance examination procedures. Based on publicly available supervisory communications, draft RFI language, and examination feedback that institutions have shared with industry associations, here is the governance documentation that banks should be prepared to produce:
- AI system inventory with materiality classifications, use case descriptions, and governance owner assignments
- Prompt change logs for all production LLM deployments in material use cases, with review and approval records
- Human oversight architecture documentation showing where human checkpoints exist, how they are enforced technically, and what the escalation path is for override or failure
- Validation evidence — red-teaming results, output distribution monitoring data, bias testing results — not just assertions that validation occurred
- Incident log for AI system failures, including near-misses where outputs were caught by human review before causing downstream harm
- Third-party model risk assessments for every vendor-provided LLM, including the vendor’s own model card, your institution’s use case restrictions, and contractual protections on data handling
If you cannot produce these documents today, you have identified your governance backlog. The good news is that the specific format requirements are not yet prescribed — which means institutions that build governance infrastructure now have latitude to design for what actually works.
Architecture Implications
For AI engineering teams: Instrument every production LLM pipeline with structured logging from day one. Retrofitting audit capability into a high-volume pipeline is expensive and often requires architecture changes that cause downtime. The marginal cost of building it in from the start is low. Add prompt version tracking to your CI/CD pipeline. Treat prompt changes as model changes.
For model risk teams: Begin developing LLM-specific validation playbooks now, before formal guidance prescribes the approach. Document your red-teaming methodology, your output monitoring framework, and your bias testing protocol. When the formal guidance arrives, you want to be defending a documented approach, not starting from scratch.
For compliance teams: Map every LLM and agentic AI deployment against the materiality framework. Any system that contributes to a lending decision, an AML determination, a sanctions screening result, or a customer communication in a regulated context is material. Start there. Document the human oversight architecture for those systems first.
For CROs and CDOs: The governance gap is documented and acknowledged by regulators. Your board should know about it. The risk is not that examiners will find AI systems — they already know banks are deploying them. The risk is that when they look for governance documentation, you cannot produce it. That gap, not the AI deployment itself, is what generates enforcement action.
The Production Reality
Banks that have built this infrastructure in production report a consistent finding: the governance investment pays for itself through operational reliability, not just regulatory compliance. Prompt versioning catches regressions before they reach customers. Output distribution monitoring detects model behavior drift before it causes systematic errors at scale. Human-in-the-loop architecture clarifies decision ownership and reduces the organizational ambiguity that causes AI incidents to escalate past their natural containment point.
The SR 11-7 framework, for all its limitations in the LLM context, was built around a sound principle: consequential decisions made by automated systems need governance instruments that allow you to understand, challenge, and control those systems. That principle doesn’t become less important because the automated system is probabilistic rather than deterministic. It becomes more important.
SR 26-2’s explicit exclusion of generative and agentic AI is not a signal that governance can wait. It is a signal that the governance framework is still being designed — and that the institutions that build operational experience governing these systems now will be in the room when the formal requirements are written.
Related Reading
- SR 26-2 Blew a Hole in Bank AI Governance — how the new guidance created the current gap
- Banking’s Model Risk Framework Wasn’t Built for LLMs — the OCC/Fed signals that formal guidance is coming
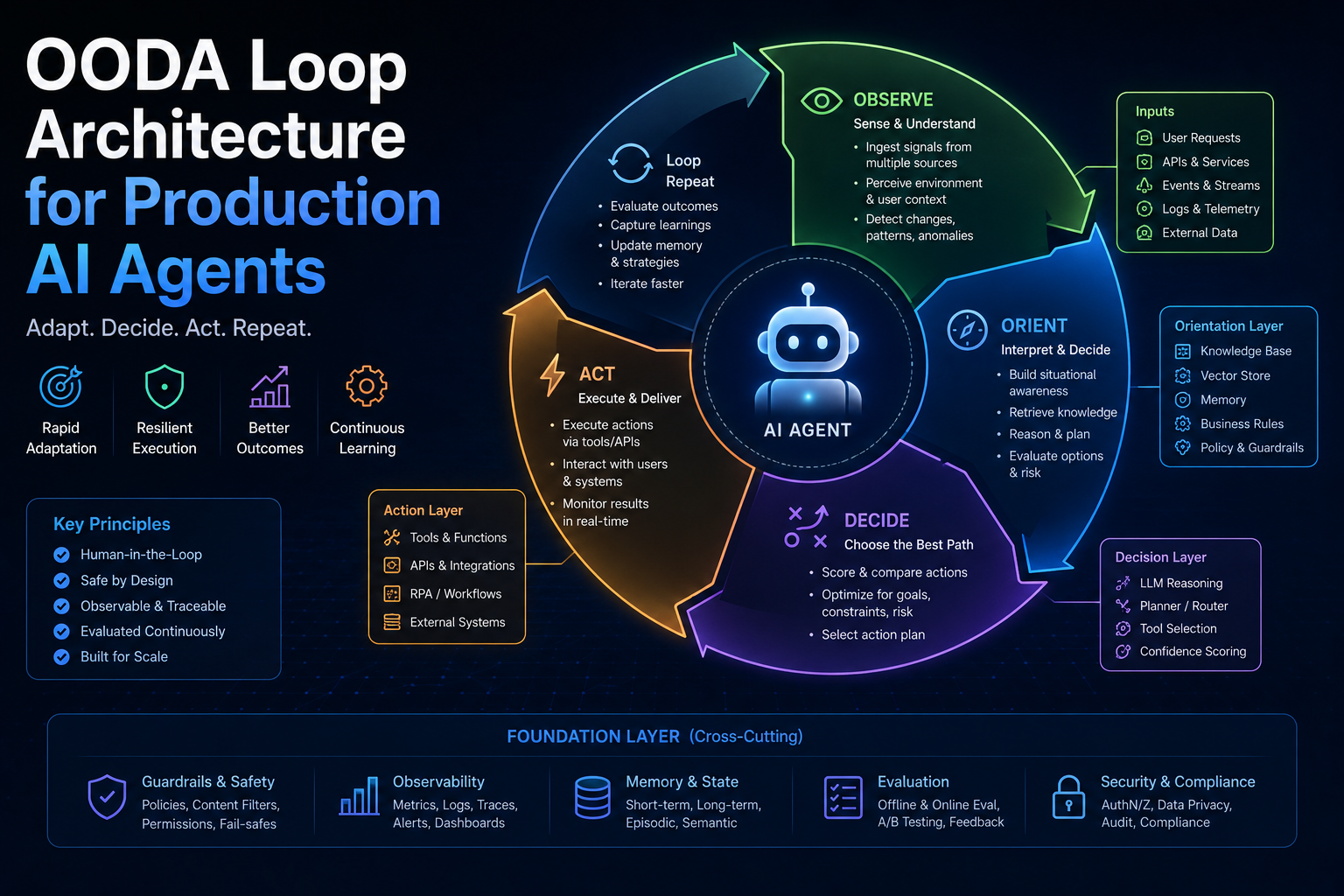
- OODA Loop Architecture for Production AI Agents — how to structure agent decision loops with built-in governance checkpoints
Enterprise AI Architecture
Want more enterprise AI architecture breakdowns?
Subscribe to SuperML.