OODA Loop Architecture for Production AI Agents
John Boyd designed the OODA loop for fighter pilots making life-or-death decisions in milliseconds with incomplete information. It turns out this is a better mental model for production AI agents than the ReAct loop — especially in high-stakes, time-pressured environments where agents need to fail fast, course-correct, and maintain situational awareness across a multi-step decision horizon.

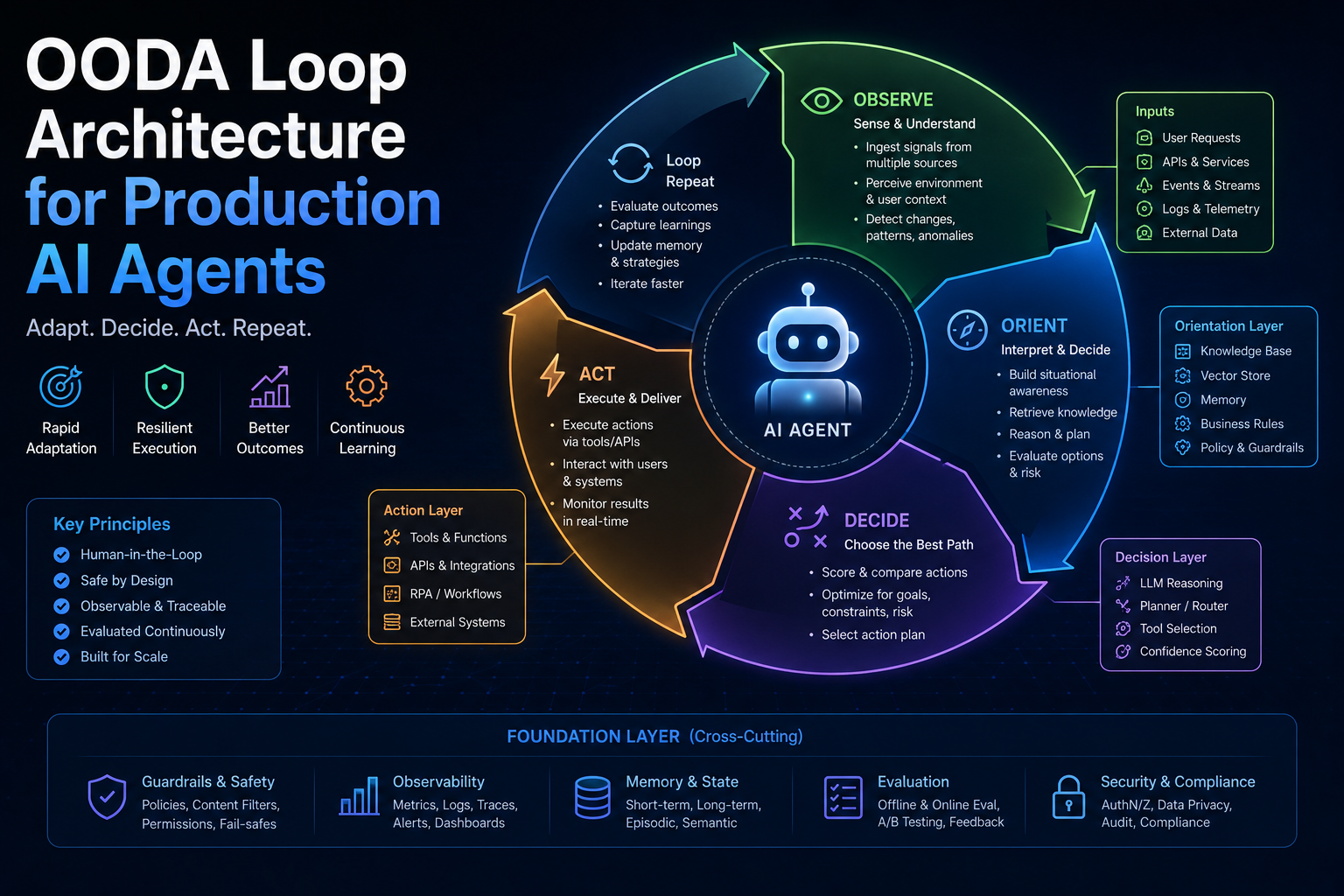
Table of Contents
The ReAct loop — Reasoning + Acting, interleaved — has become the default mental model for AI agents. The agent reasons about the current state, selects a tool, observes the result, reasons again, and continues until it reaches a terminal state or hits a step limit. It’s clean, it’s documented, and it’s the basis for most agent frameworks available today.
It’s also a poor fit for the class of agents that matter most in enterprise environments: agents operating under real-time pressure, partial information, adversarial conditions, and high-consequence outcomes where wrong decisions compound faster than the agent can correct them.
John Boyd didn’t design the OODA loop for clean, sequential decision problems. He designed it for fighter pilots making kinetic decisions in milliseconds with radar contacts that might be friendly, hostile, or sensor artifacts — in an environment where the penalty for a wrong decision is immediate and irreversible. The framework he built is not sequential reasoning to action. It is a continuous, parallel loop that emphasizes orientation — the mental model that governs how observations are interpreted — as the most important and most vulnerable part of the decision system.
That is exactly the architecture problem that production AI agents have, and that the ReAct framing systematically understates.
What the OODA Loop Actually Is (Not What the Slides Say)
Most OODA loop presentations show it as four boxes in a circle: Observe → Orient → Decide → Act → repeat. That is the tourist version. The actual Boyd model is more complex and more useful.
In Boyd’s original briefing, the OODA loop has two critical properties that the four-box diagram erases:
1. Implicit guidance and control. The loop doesn’t always complete all four stages explicitly. In experienced operators under time pressure, Observation can flow directly to Action — bypassing explicit Orient and Decide phases — because the operator’s trained orientation already contains the decision logic. This is not a failure mode; it is an optimization. The question for AI agents is: when should the agent execute implicit guidance (fast pattern-matching to action) vs. explicit reasoning (full OODA cycle)?
2. Orientation dominates everything. Boyd’s key insight was that Orientation — the synthesis of cultural traditions, prior experiences, mental models, and incoming data — is not just one phase of the loop. It is the lens through which every other phase operates. A pilot with a wrong orientation will observe the same radar contact as every other pilot and draw a different, worse conclusion. The loop cycles fast, but if Orientation is miscalibrated, it cycles fast toward the wrong decision.
For AI agents, this maps directly: the system prompt, the retrieved context, the agent’s “beliefs” about the current state — these are the Orientation layer. An agent with a miscalibrated Orientation (outdated context, wrong prior, hallucinated state) will reason correctly within its frame and arrive at the wrong answer every time.
The Production Architecture
Here is the OODA-based agent architecture I’ve implemented in production environments, including the SmartCIO platform. The pattern is most applicable to agents operating in enterprise workflows with real-time data, multiple tool integrations, and human-in-the-loop checkpoints.
┌─────────────────────────────────────────────────────────┐
│ OODA Agent Runtime │
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ OBSERVE │───▶│ ORIENT │───▶│ DECIDE │ │
│ │ │ │ │ │ │ │
│ │ Sensors │ │ Context │ │ Planner │ │
│ │ Tools │ │ Fusion │ │ Ranker │ │
│ │ Streams │ │ World │ │ Guard │ │
│ │ │ │ Model │ │ │ │
│ └──────────┘ └──────────┘ └────┬─────┘ │
│ ▲ │ │
│ │ ┌──────────┐ │ │
│ └──────────│ ACT │◀────────┘ │
│ │ │ │
│ │ Executor │ │
│ │ Verifier │ │
│ │ Auditor │ │
│ └──────────┘ │
│ │
│ ┌─────────────────────────────────────────────────┐ │
│ │ Orientation Layer (Persistent) │ │
│ │ World Model · Prior Context · Tool State │ │
│ │ Constraints · Risk Thresholds · Memory │ │
│ └─────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────┘The key architectural decision that distinguishes this from a ReAct loop is the Orientation Layer as a first-class persistent component — not just the current chain-of-thought, but an explicit, updateable world model that persists across tool calls and loop iterations.
The Observe Phase: Multi-Signal Sensing
In ReAct, observation is typically the return value of the last tool call. In the OODA architecture, observation is a multi-signal aggregation step that runs in parallel.
class ObservePhase:
def __init__(self, sensors: list[Sensor]):
self.sensors = sensors
async def observe(self, context: AgentContext) -> Observation:
# All sensors run in parallel — don't serialize observation
raw_signals = await asyncio.gather(
*[sensor.read(context) for sensor in self.sensors],
return_exceptions=True
)
# Separate valid signals from failed sensors
valid_signals = [s for s in raw_signals if not isinstance(s, Exception)]
failed_sensors = [s for s in raw_signals if isinstance(s, Exception)]
return Observation(
signals=valid_signals,
failed_sensors=failed_sensors,
timestamp=datetime.utcnow(),
confidence=self._compute_confidence(valid_signals, failed_sensors)
)
def _compute_confidence(self, valid, failed) -> float:
# Low confidence when key sensors are offline
critical_failures = sum(1 for s in failed if getattr(s, 'critical', False))
return 1.0 - (critical_failures * 0.3)The confidence field on the Observation is not decoration. It gates the downstream Orient and Decide phases. An observation with confidence below a threshold triggers a different decision path — slow down, escalate, or wait for more signal — rather than proceeding with a low-quality world-model update.
This is the design principle that most ReAct implementations miss: the agent should explicitly model the quality of its own observations and adjust its decision-making accordingly, rather than treating every tool response as equally reliable.
The Orient Phase: World Model Maintenance
This is where the OODA architecture diverges most sharply from ReAct. Rather than updating a chain-of-thought string, Orient explicitly maintains a structured world model.
@dataclass
class WorldModel:
# Current task state
task_objective: str
completed_steps: list[Step]
pending_hypotheses: list[Hypothesis]
# Environmental state
known_facts: dict[str, FactWithConfidence]
contradictions: list[Contradiction] # Track inconsistencies explicitly
# Risk state
irreversible_actions_taken: list[Action]
active_constraints: list[Constraint]
risk_budget_remaining: float
# Temporal state
loop_count: int
elapsed_ms: int
deadline: Optional[datetime]
class OrientPhase:
def __init__(self, llm: LLM, memory: AgentMemory):
self.llm = llm
self.memory = memory
async def orient(
self,
observation: Observation,
world_model: WorldModel
) -> OrientationResult:
# Detect contradictions before updating world model
contradictions = self._detect_contradictions(observation, world_model)
if contradictions:
# Don't silently override prior beliefs — surface the conflict
return OrientationResult(
updated_model=world_model,
contradictions=contradictions,
requires_human_review=any(c.severity == 'high' for c in contradictions),
orientation_confidence=0.4
)
# Update world model with new observations
updated_model = await self.llm.update_world_model(
current_model=world_model,
new_observation=observation,
relevant_memory=await self.memory.retrieve(observation)
)
return OrientationResult(
updated_model=updated_model,
contradictions=[],
requires_human_review=False,
orientation_confidence=observation.confidence * 0.9
)
def _detect_contradictions(
self,
obs: Observation,
model: WorldModel
) -> list[Contradiction]:
contradictions = []
for signal in obs.signals:
for key, known_fact in model.known_facts.items():
if signal.contradicts(known_fact):
contradictions.append(Contradiction(
new_signal=signal,
prior_belief=known_fact,
severity='high' if known_fact.confidence > 0.8 else 'low'
))
return contradictionsThe explicit contradiction detection is the mechanism that prevents the agent from building a house of cards. In production environments, tool responses are often inconsistent — a database query returns a different count than a summary API, a document retrieval returns context that conflicts with the agent’s prior memory. An agent that silently incorporates contradictions into its world model compounds the error. An agent that surfaces contradictions and pauses for review contains it.
The Decide Phase: Structured Planning with Risk Gating
The Decide phase takes the oriented world model and produces a plan — but in the OODA architecture, planning is gated by explicit risk assessment before execution.
class DecidePhase:
def __init__(self, planner: LLM, risk_engine: RiskEngine):
self.planner = planner
self.risk_engine = risk_engine
async def decide(
self,
orientation: OrientationResult,
world_model: WorldModel
) -> Decision:
# Refuse to decide if orientation confidence is too low
if orientation.orientation_confidence < 0.3:
return Decision.escalate(
reason="Insufficient orientation confidence",
context=orientation
)
# Generate candidate actions
candidates = await self.planner.generate_candidates(
world_model=orientation.updated_model,
n_candidates=3 # Generate alternatives, don't commit to first option
)
# Risk-gate each candidate
risk_assessments = await asyncio.gather(
*[self.risk_engine.assess(c, world_model) for c in candidates]
)
# Filter by risk budget and reversibility
viable_candidates = [
(c, r) for c, r in zip(candidates, risk_assessments)
if r.estimated_cost <= world_model.risk_budget_remaining
and (not r.is_irreversible or world_model.has_human_approval(c))
]
if not viable_candidates:
return Decision.escalate(
reason="No viable candidates within risk budget",
context={"candidates": candidates, "assessments": risk_assessments}
)
# Select highest-value viable candidate
best_candidate, best_risk = max(
viable_candidates,
key=lambda x: x[1].expected_value
)
return Decision(
action=best_candidate,
risk_assessment=best_risk,
alternatives_considered=candidates,
confidence=orientation.orientation_confidence * best_risk.confidence
)Three design decisions here that matter in production:
Generate candidates, don’t commit to the first option. The ReAct loop typically produces one action per cycle. The OODA Decide phase generates multiple candidates and selects among them after risk assessment. This is slower, but it produces better decisions in complex environments — and it documents that alternatives were considered, which matters for governance.
Irreversible actions require human approval tokens. Any action that cannot be undone — a transaction, a case closure, a filed document — requires explicit human approval before the Decide phase will return it as a viable option. The approval isn’t advisory; the architecture enforces it structurally. No token, no action.
Risk budget maintenance. The world model tracks a risk budget — a quantitative proxy for the agent’s license to act autonomously. Each action consumes risk budget based on its uncertainty, cost, and reversibility. When the budget is exhausted, the agent cannot take further consequential actions until a human reviews and resets it.
The Act Phase: Execute, Verify, Audit
The Act phase executes the selected action, but adds two components that the ReAct loop typically omits: post-execution verification and structured audit logging.
class ActPhase:
def __init__(self, executor: ToolExecutor, auditor: AuditLogger):
self.executor = executor
self.auditor = auditor
async def act(
self,
decision: Decision,
world_model: WorldModel
) -> ActionResult:
# Log intent before execution (important for audit — captures what was planned)
await self.auditor.log_intent(
decision=decision,
world_model_snapshot=world_model,
timestamp=datetime.utcnow()
)
# Execute
try:
raw_result = await self.executor.execute(decision.action)
except Exception as e:
await self.auditor.log_failure(decision, e)
return ActionResult.failure(decision, e)
# Post-execution verification
verified = await self._verify_result(raw_result, decision)
# Log outcome (captures what actually happened — may differ from intent)
await self.auditor.log_outcome(
decision=decision,
result=raw_result,
verified=verified,
timestamp=datetime.utcnow()
)
# Update risk budget based on actual cost
world_model.risk_budget_remaining -= verified.actual_cost
return ActionResult(
result=raw_result,
verification=verified,
risk_consumed=verified.actual_cost
)
async def _verify_result(
self,
result: ToolResult,
decision: Decision
) -> VerificationResult:
# Check that the result matches what the decision expected
# Surface discrepancies as observations for the next OODA cycle
expected = decision.action.expected_postcondition
actual = result.postcondition
return VerificationResult(
matches_expected=self._postconditions_match(expected, actual),
actual_cost=result.resource_cost,
discrepancies=self._compute_discrepancies(expected, actual)
)The split between intent logging (before execution) and outcome logging (after execution) is the governance instrument that allows you to reconstruct the full reasoning chain for any agent action. Intent logs capture what the agent planned and why. Outcome logs capture what actually happened. The gap between them — when it exists — is the most important signal for debugging, validation, and examination response.
Where the OODA Loop Architecture Breaks Down
Honesty requires documenting the failure modes alongside the design.
It’s slower than ReAct for simple tasks. The multi-signal observe, world-model update, candidate generation, and risk-gating add latency. For a simple retrieval task where a single tool call is sufficient, the OODA overhead is wasteful. The architecture is designed for complex, multi-step, high-stakes workflows — not for every agent use case.
World model maintenance is expensive at scale. Keeping a structured world model in memory and updating it coherently across many loop iterations requires careful context management. At 15+ OODA cycles, the world model approaches context limits in current LLMs. The solution is aggressive world model compression — summarizing prior steps while preserving the key facts — but this introduces its own failure mode when the compression discards something that was important.
Contradiction detection can be over-triggering. In environments with noisy or inconsistent data sources, the contradiction detector can block progress by flagging conflicts that are not actually meaningful. Tuning the contradiction threshold is a per-deployment calibration problem that requires operational experience with the specific data sources involved.
Human-in-the-loop gates create bottlenecks. The irreversible-action approval gate is the right governance design, but it means that high-throughput workflows — AML triage, document processing, batch case work — require either very fast human review cycles or a differentiated approval architecture where lower-risk irreversible actions have a lighter approval path. This is an organizational design problem as much as a technical one.
Production Deployment Pattern
For enterprise deployments, I use the following pattern to instantiate the OODA runtime:
class OODAAgentRuntime:
def __init__(self, config: OODAConfig):
self.observe = ObservePhase(sensors=config.sensors)
self.orient = OrientPhase(llm=config.llm, memory=config.memory)
self.decide = DecidePhase(
planner=config.planner_llm,
risk_engine=RiskEngine(thresholds=config.risk_thresholds)
)
self.act = ActPhase(
executor=ToolExecutor(tools=config.tools),
auditor=AuditLogger(sink=config.audit_sink)
)
async def run(
self,
objective: str,
initial_context: dict,
max_loops: int = 20
) -> AgentResult:
world_model = WorldModel.initialize(
task_objective=objective,
initial_context=initial_context,
risk_budget=self.config.risk_budget
)
for loop_count in range(max_loops):
world_model.loop_count = loop_count
# Full OODA cycle
observation = await self.observe.observe(world_model.to_context())
orientation = await self.orient.orient(observation, world_model)
if orientation.requires_human_review:
return AgentResult.pause_for_review(world_model, orientation)
decision = await self.decide.decide(orientation, world_model)
if decision.is_escalation:
return AgentResult.escalate(world_model, decision)
if decision.action.is_terminal:
return AgentResult.complete(world_model, decision)
action_result = await self.act.act(decision, world_model)
world_model = world_model.update(orientation, action_result)
# Max loops exceeded — escalate, don't silently fail
return AgentResult.max_loops_exceeded(world_model)The terminal conditions — human review, escalation, completion, max loops — are all explicit. The agent does not loop indefinitely, does not silently fail, and does not make consequential decisions when its orientation confidence is below threshold. These are not just good engineering practices. They are the governance controls that make the system auditable.
OODA vs. ReAct: When to Use Which
| Characteristic | ReAct | OODA |
|---|---|---|
| Task complexity | Simple to moderate | Complex, multi-step |
| Information quality | Reliable tools, low noise | Noisy, inconsistent, or adversarial inputs |
| Consequence level | Low — errors are recoverable | High — errors have downstream impact |
| Governance requirements | Lightweight audit | Full audit trail required |
| Latency budget | Tight | Moderate to flexible |
| Human oversight | Not required | Required for material actions |
For most chatbot and simple RAG applications, ReAct is sufficient and faster. For enterprise workflows touching regulated decisions — AML triage, credit analysis, compliance research, trading signal generation — the OODA architecture’s explicit orientation management, contradiction detection, risk gating, and audit logging are not optional complexity. They are the production requirements.
The SmartCIO Implementation
The SmartCIO platform implements the OODA runtime as its core decision engine for portfolio analysis and market intelligence workflows. The multi-LLM routing layer (Anthropic + OpenAI + Ollama) feeds the Observe phase as parallel sensors. The Orient phase maintains a persistent world model that spans market data, portfolio state, and risk thresholds. The Decide phase is gated by position size limits and regulatory constraints. The Act phase logs every decision intent and outcome to a structured audit trail.
The most important production lesson from that deployment: the Orientation Layer — specifically, the contradiction detection and world model update logic — is where 80% of agent bugs surface. Not in tool execution. Not in reasoning. In the gap between what the agent believes about the current state and what is actually true.
Boyd was right. Orientation is the dominant element of the loop. The architectures that treat it as a first-class component build better agents. The architectures that treat it as the implicit state of a chain-of-thought string discover that lesson the hard way, in production, at the worst possible time.
Related Reading
- SR 11-7 Model Risk for AI Systems: What Banks Actually Need — governance framework for OODA-based agent deployments in regulated environments
- Multi-Agent Orchestration Patterns for Enterprise — how OODA agents compose with supervisor patterns
- AI Governance for Financial Services — the full governance context for production agent architecture
Enterprise AI Architecture
Want more enterprise AI architecture breakdowns?
Subscribe to SuperML.