LangChain Workflow Management: Production Patterns with LangGraph, Agents, Retries, Memory, and Observability
A production architecture guide for LangChain workflow management: how to combine LangChain and LangGraph, decide between workflows and agents, and design retries, state, memory, observability, human review, security, and cost controls.

Table of Contents
Most teams start with a demo chain or agent and then discover the hard part in production: workflow management under failure, latency, cost, security, and governance constraints.
The architectural question is not “Can LangChain call tools?” It is “Can this workflow run reliably at scale, with predictable cost, bounded autonomy, recoverable state, and enough visibility to debug incidents quickly?”
This guide covers practical workflow architecture decisions for production AI agents using LangChain and LangGraph.
Why Workflow Management Is a First-Class Architecture Concern
Production AI workflows combine model calls, tool calls, state transitions, and policy checks. Failures compound across those boundaries.
A single user request can include:
- Intent classification
- Retrieval
- Planning
- Multi-step tool execution
- Validation
- Final response assembly
Each step adds latency, cost, and error surface. Workflow management is how you keep this complexity bounded.
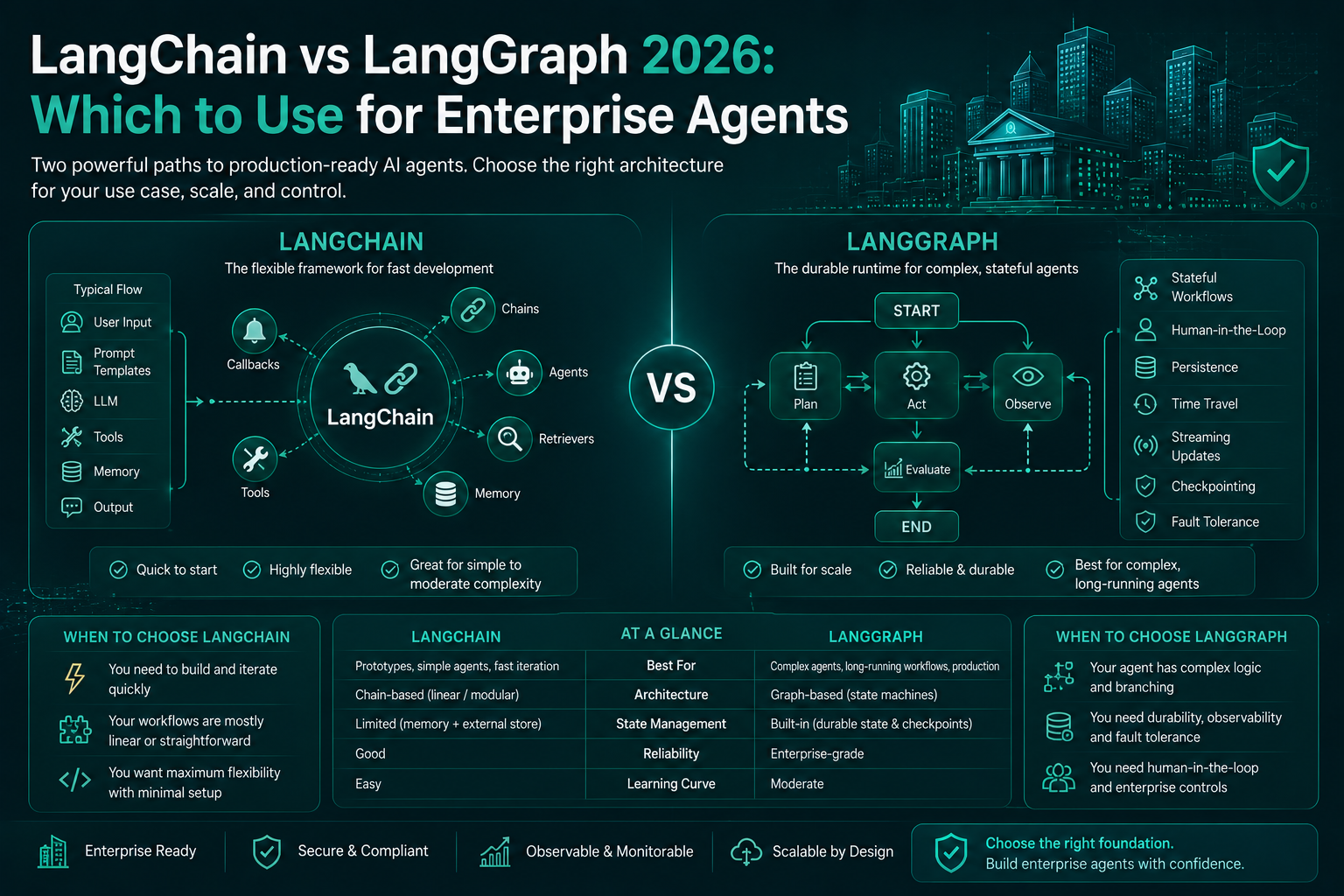
LangChain vs LangGraph: Application Framework vs Agent Runtime
LangChain and LangGraph are not an either-or decision. In production systems, they usually serve different layers of the same architecture.
LangChain strength
LangChain is useful when you want to build LLM applications and agents quickly using prebuilt abstractions, model integrations, prompt templates, tool adapters, retrievers, and common agent patterns.
Use it when:
- You need fast application assembly.
- The flow is mostly linear or shallow.
- Tool usage is simple and bounded.
- State does not need durable recovery between steps.
- You want reusable components across multiple LLM applications.
LangGraph strength
LangGraph is better when workflow control itself becomes a production requirement: branching, loops, explicit state transitions, checkpointed execution, human-in-the-loop review, resumability, and replay.
Use it when:
- You need explicit state machines or graph-based orchestration.
- You need deterministic transitions and recovery paths.
- You need durable checkpoints and resumable execution.
- You need long-running or interruptible agent tasks.
- You need approval gates before sensitive tool calls.
Practical decision rule
- Use LangChain when speed of application assembly matters most.
- Use LangGraph when state, control flow, recovery, and governance matter most.
- Use both when LangChain handles the application and agent abstractions while LangGraph handles the execution graph underneath.
This avoids overengineering early and underengineering later.
Workflow vs Agent Decision
Not every use case needs an open-ended agent.
Choose a workflow when:
- Steps are known ahead of time.
- You can define explicit success criteria.
- Compliance requires deterministic execution boundaries.
Choose an agent when:
- Tool choice depends on runtime context.
- Task decomposition is dynamic.
- The task has unknown intermediate states.
Hybrid pattern for production:
- Deterministic workflow for guardrails and high-risk boundaries.
- Agentic subgraph for bounded reasoning zones.
In other words, do not let the agent own the whole system. Let the workflow own permissions, validation, state transitions, escalation, and recovery. Let the agent reason only inside bounded zones where uncertainty is expected.
This gives flexibility without sacrificing control.
Retries, State, Memory, and Tool Calls
Retries
Retries should be class-aware, not global.
- Retry transient network or rate-limit errors.
- Do not blindly retry semantic failures.
- Add exponential backoff and jitter.
- Cap retry budgets per request to avoid runaway cost.
State management
Separate state into three scopes:
- Request state: ephemeral values for a single run.
- Session state: conversation context across turns.
- System state: durable workflow checkpoints and approvals.
Mixing these scopes causes most production regressions.
Memory strategy
Memory is expensive and risky without boundaries.
- Keep short memory for current objective.
- Store long memory in retrieval systems with metadata filters.
- Add TTL and redaction policies for sensitive artifacts.
Tool-call discipline
Every tool call should have:
- Input schema validation
- Output schema validation
- Timeout budgets
- Idempotency expectations
- Least-privilege credentials
- Tool allowlists by workflow stage
- Clear failure semantics
Treat tools like external distributed systems, not local helper functions.
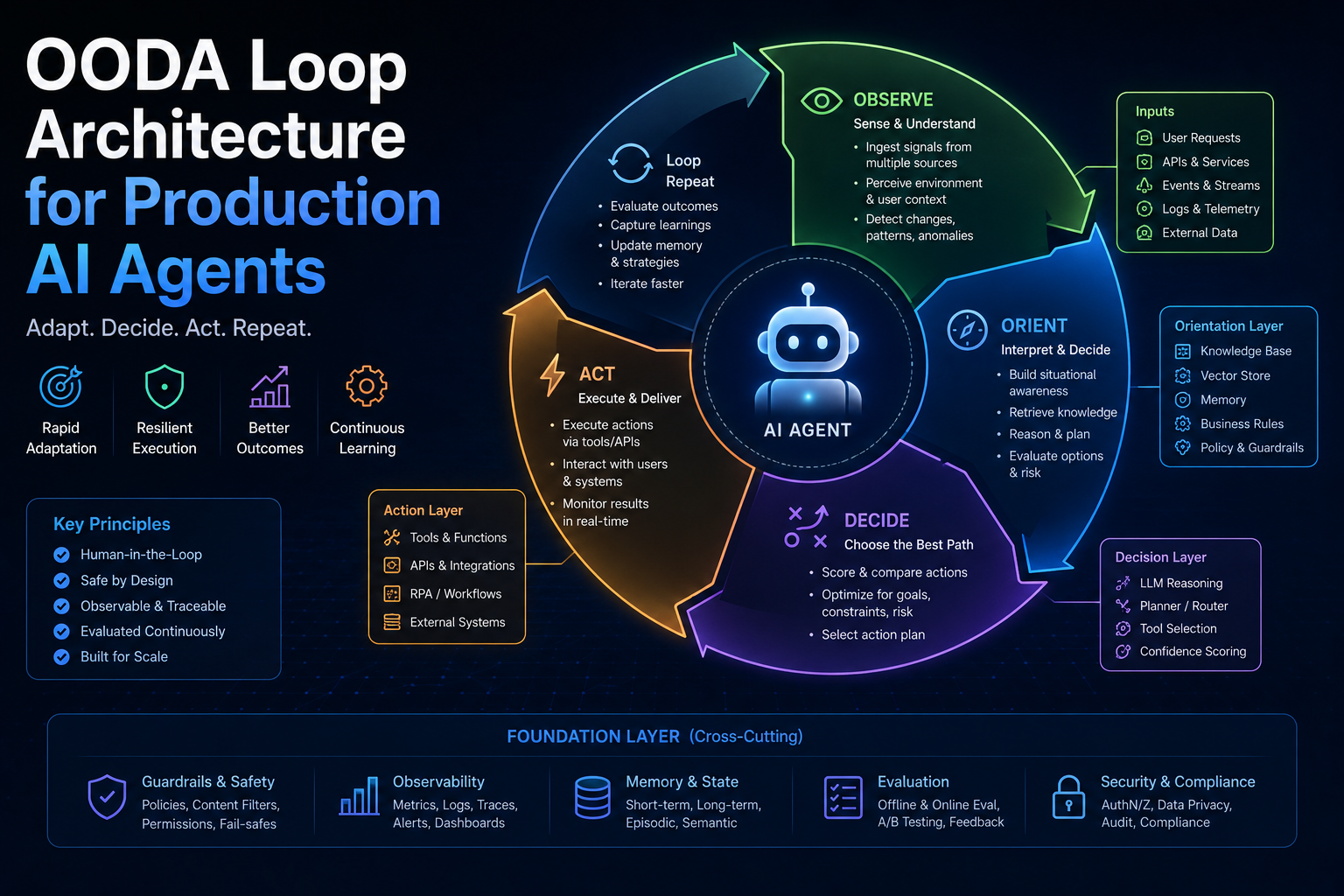
Observability for Workflow Reliability
You cannot improve what you cannot trace.
At minimum, instrument:
- Step-level latency
- Token usage by step
- Tool failure rate
- Retry count by exception class
- Model and prompt version
- Retrieval source and citation quality
- Human approval decisions
- Policy decision logs
- Final success/failure outcomes
Make traces joinable across model and tool boundaries with a single request correlation ID. Use LangSmith, OpenTelemetry, or your internal observability platform to capture traces across model calls, tool calls, retrieval, validation, policy checks, and final response generation.
Operationally, this enables:
- Fast root-cause analysis
- Cost hotspot identification
- Regression detection after prompt/model updates
Cost Control Patterns for LangChain Workflows
Cost overruns typically come from hidden loops, long prompts, and unnecessary high-tier model usage.
Add these controls:
- Model routing tiers
- Small models for classification and extraction.
- Mid-tier models for synthesis.
- Frontier models only for high-ambiguity reasoning.
- Token budgets per stage
- Hard cap input and output tokens per step.
- Fail fast when a stage exceeds budget.
- Retry budgets
- Track cumulative retry cost per request.
- Stop retries when marginal utility drops.
- Prompt compaction
- Compress context before expensive reasoning stages.
- Keep tool payloads minimal and schema-focused.
- Cache strategy
- Cache deterministic retrieval and transformation outputs.
- Avoid recomputing stable intermediate artifacts.
Human-in-the-Loop Controls
Human review is not a weakness in production agent design. It is a control point for high-risk decisions.
Add approval gates before actions such as:
- Sending external communications
- Updating customer records
- Executing SQL against production data
- Deleting or overwriting files
- Triggering payments or financial transactions
- Calling tools that expose sensitive information
The workflow should pause, show the proposed action, capture approval or rejection, and then resume from a durable checkpoint. This is where LangGraph-style stateful orchestration becomes valuable.
For low-risk paths, automate fully. For high-impact paths, use controlled autonomy: the agent can recommend and prepare actions, but the workflow decides when human approval is required.
Security and Governance Controls
Production agent workflows should assume that model outputs, tool responses, retrieved documents, and user inputs are all untrusted until validated.
Add controls for:
- Prompt injection detection and isolation
- Tool allowlists by workflow stage
- Least-privilege credentials per tool
- SQL validation before execution
- Human approval for irreversible actions
- Secrets redaction in traces and logs
- Dependency scanning and version pinning
- Audit logs for policy decisions and tool calls
The safest production pattern is not “let the agent decide everything.” It is controlled autonomy: the agent can reason inside a bounded execution environment, but the workflow owns permissions, validation, escalation, and recovery.
Production Failure Modes and Mitigations
1) Silent semantic drift
Symptom:
- Workflow succeeds technically but quality degrades after model updates.
Mitigation:
- Golden-set regression tests
- Model version pinning for critical paths
- Automatic canary comparisons
2) Retry storms
Symptom:
- Transient upstream incident multiplies request cost and latency.
Mitigation:
- Circuit breakers
- Retry budgets
- Graceful degradation responses
3) Tool-call cascades
Symptom:
- One tool timeout causes multi-step downstream failures.
Mitigation:
- Per-tool timeout and fallback path
- Dependency graph health checks
- Partial completion policies
4) Memory contamination
Symptom:
- Incorrect prior context influences unrelated tasks.
Mitigation:
- Memory scope boundaries
- Task-level memory isolation
- Explicit memory reset events
5) Observability blind spots
Symptom:
- Incident response cannot identify failing stage quickly.
Mitigation:
- Standardized step instrumentation
- Unified trace IDs
- Policy and model telemetry in one timeline
6) Unsafe tool autonomy
Symptom:
- The agent calls tools outside the intended scope or takes irreversible actions without enough review.
Mitigation:
- Tool allowlists by workflow state
- Human approval gates for sensitive operations
- Least-privilege tool credentials
- Explicit policy checks before execution
Reference Production Architecture
A resilient LangChain production stack usually has:
- Application layer using LangChain components
- Graph orchestration layer using LangGraph-style stateful execution
- Model routing gateway
- Tool gateway with policy checks
- State and checkpoint store
- Retrieval/memory subsystem
- Human approval queue for sensitive actions
- Telemetry, evaluation, and alerting pipeline
Keep orchestration logic in version-controlled code, not only in ad hoc notebooks or UI builders.
Example: Customer Support Agent Workflow
Recommended layout:
- Intent + risk classification using a small model
- Retrieval and policy grounding
- Deterministic workflow branch
- low-risk: fast auto-response path
- medium-risk: bounded agentic reasoning with strict tool scope
- high-risk: human approval before action
- Validation and citation checks
- Human escalation gate when confidence drops or policy risk increases
- Response assembly and trace persistence
This pattern gives speed on common requests and safety on high-impact requests.
Implementation Checklist
Before promoting to production, verify:
- Workflow vs agent boundary is explicit
- LangChain vs LangGraph responsibilities are clear
- Retries are bounded and class-aware
- Tool contracts are schema-validated
- Tool permissions are scoped by workflow stage
- Memory has scope and retention controls
- Human approval gates exist for sensitive actions
- Traces include every stage, policy decision, and cost signal
- Golden-set regression is automated
- Dependency versions are pinned and scanned
- Failover behavior is tested
If two or more items are missing, reliability issues will appear at moderate scale.
Final Take
LangChain can absolutely support production AI agents, especially when combined with LangGraph for stateful orchestration, but only when workflow management is treated as architecture, not glue code.
Use deterministic workflows where you need control, bounded agentic loops where you need flexibility, human approval where actions are sensitive, and instrumentation across every stage like a distributed system.
That is how you move from demo velocity to production reliability.
Related Reading
Enterprise AI Architecture
Want more enterprise AI architecture breakdowns?
Subscribe to SuperML.