Supervised Learning: A Beginner-Friendly Guide with Examples Decoded: The Complete Guide That Will Make You an Expert!

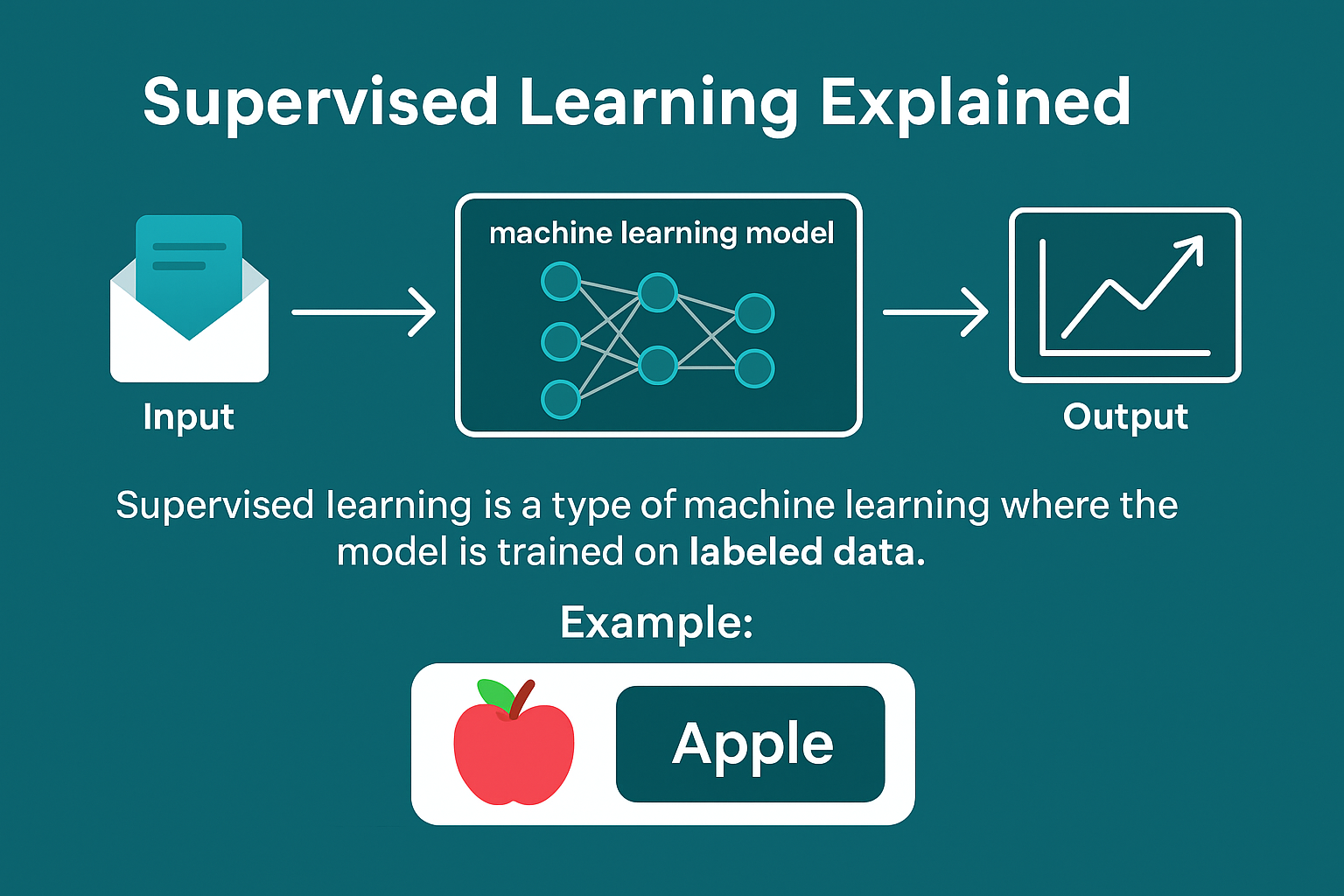
Table of Contents
🧠 What is Supervised Learning?
Supervised learning is one of the most common and powerful types of machine learning. It involves training a model on a labeled dataset, which means each input has a corresponding correct output.
📌 Example: You give the model a set of house features (like size, number of rooms) and the price it sold for. The model learns to predict the price of new houses based on that.
Supervised Vs Unsupervised Learning:
📂 Types of Supervised Learning
There are two main types:
1. Classification
Used when the output is a category.
- ✅ Example: Email spam detection — is it “spam” or “not spam”?
2. Regression
Used when the output is a number.
- 🏠 Example: Predicting house prices or stock values.
🧪 Popular Algorithms
| Type | Algorithms |
|---|---|
| Classification | Logistic Regression, Decision Trees, Random Forest, Support Vector Machines (SVM), KNN |
| Regression | Linear Regression, Decision Trees, Random Forest, SVR |
💻 Code Example (Python - Classification)
Here’s how you can classify iris flowers using sklearn:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Load dataset
data = load_iris()
X = data.data
y = data.target
# Split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Model
model = RandomForestClassifier()
model.fit(X_train, y_train)
# Predict
y_pred = model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))💡 Tips for Using Supervised Learning
- Ensure your dataset has high-quality, correctly labeled data.
- Normalize or scale features when needed (especially for distance-based models like KNN or SVM).
- Use cross-validation to evaluate your model’s performance.
- Visualize decision boundaries (for 2D data) to understand what your model is learning.
🌍 Real-World Applications
- Fraud detection in banking
- Disease diagnosis in healthcare
- Sentiment analysis on social media
- Stock price prediction
- Image recognition (e.g., digit classification)
🚧 Challenges
- Overfitting: Model performs well on training data but poorly on new data.
- Bias in Labels: Incorrect or biased labels can mislead the model.
- Imbalanced Classes: Some classes have too few examples.
🧭 Conclusion
Supervised learning is the backbone of many AI applications. Once you understand the difference between classification and regression and know how to use tools like scikit-learn, you can begin building real-world models quickly.
Want to explore more? Try building a spam classifier or a price prediction model using your own dataset!
Related Reading
Enterprise AI Architecture
Want more enterprise AI architecture breakdowns?
Subscribe to SuperML.
