LangChain Document Loaders & Vector Stores: Powering RAG Applications
Learn how to use document loaders, text splitters, and vector stores in LangChain to enable retrieval-augmented generation (RAG) and semantic search.

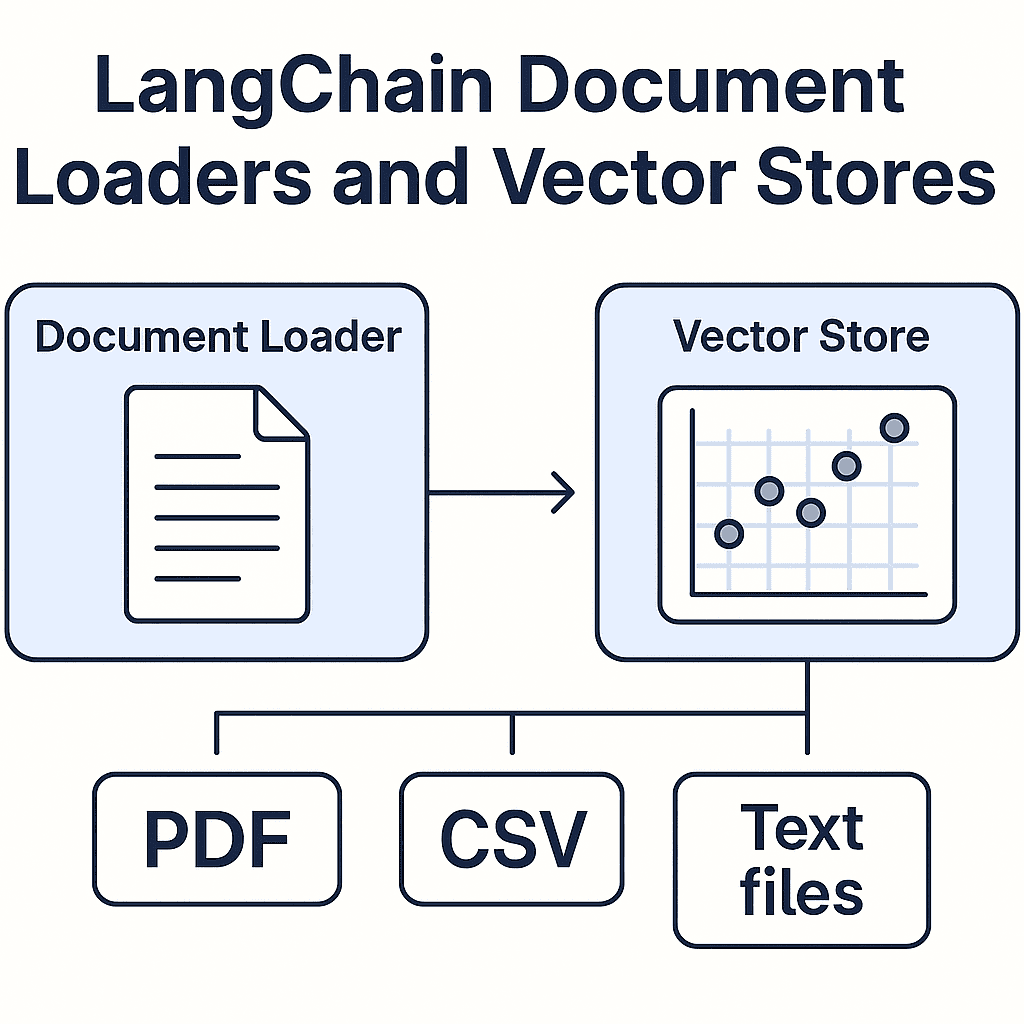
Table of Contents
Unlock the power of Retrieval-Augmented Generation (RAG) by combining external knowledge with LLMs using LangChain’s document loaders and vector stores.
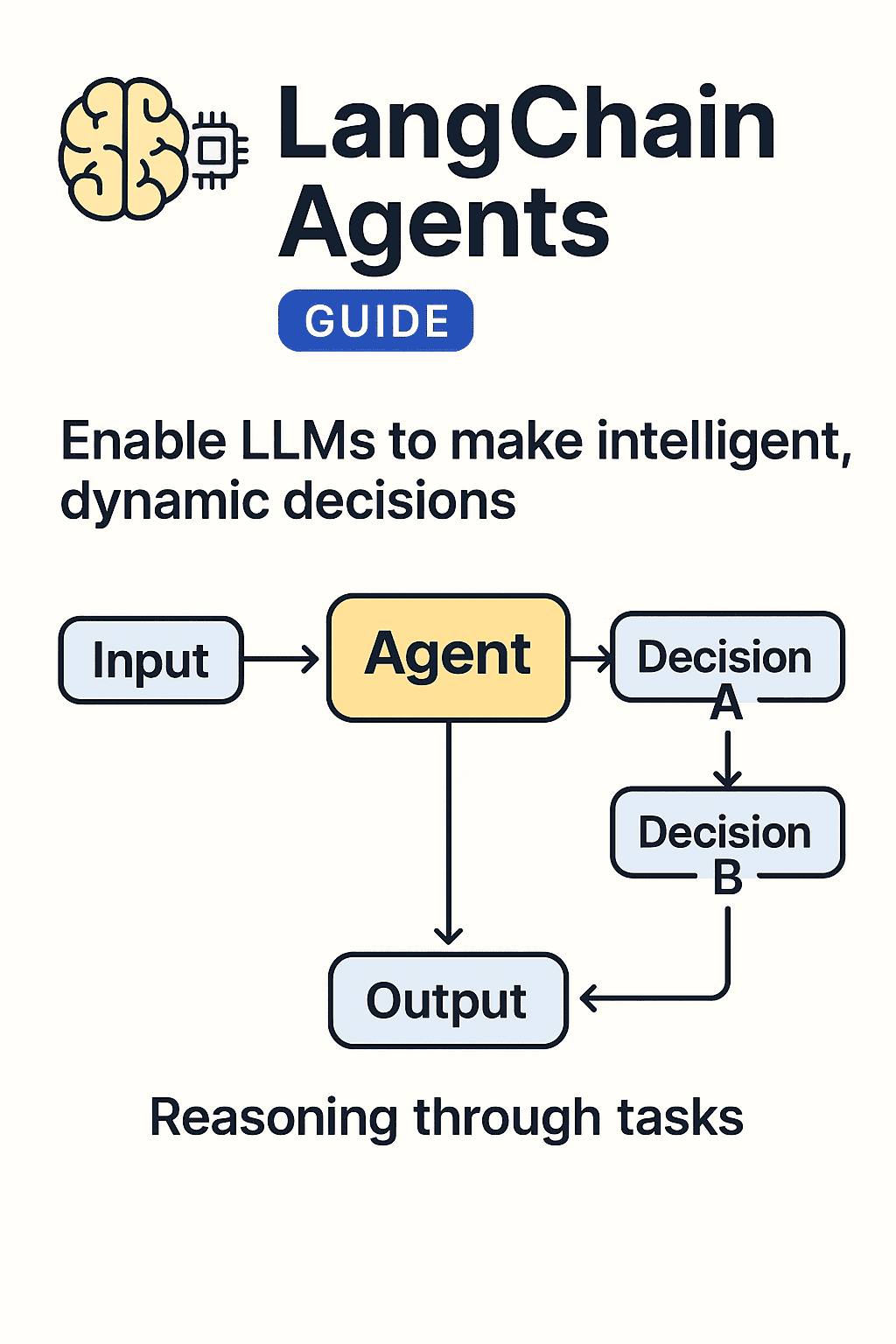
🔍 What Are Document Loaders in LangChain?
Document loaders let you ingest data from various formats such as:
- PDFs
- Web pages
- YouTube transcripts
- Notion, Slack, Confluence
- Markdown, CSV, DOCX
They convert raw input into clean Document objects containing:
- .page_content
- .metadata
✂️ Splitting Text into Chunks
Large documents are split into smaller chunks using TextSplitter, allowing each chunk to be embedded and indexed individually.
Common strategies:
- RecursiveCharacterTextSplitter
- TokenTextSplitter
Why split?
- LLMs have token limits
- Improves retrieval relevance
- Faster indexing and searching
🧠 What Are Vector Stores?
Vector stores are databases optimized for similarity search using embeddings. LangChain supports:
- FAISS (local, fast)
- ChromaDB (lightweight, local)
- Pinecone (cloud-hosted)
- Weaviate, Qdrant, Milvus (enterprise-scale)
These stores map text chunks to high-dimensional vectors using an embedding model (e.g., OpenAI, HuggingFace).
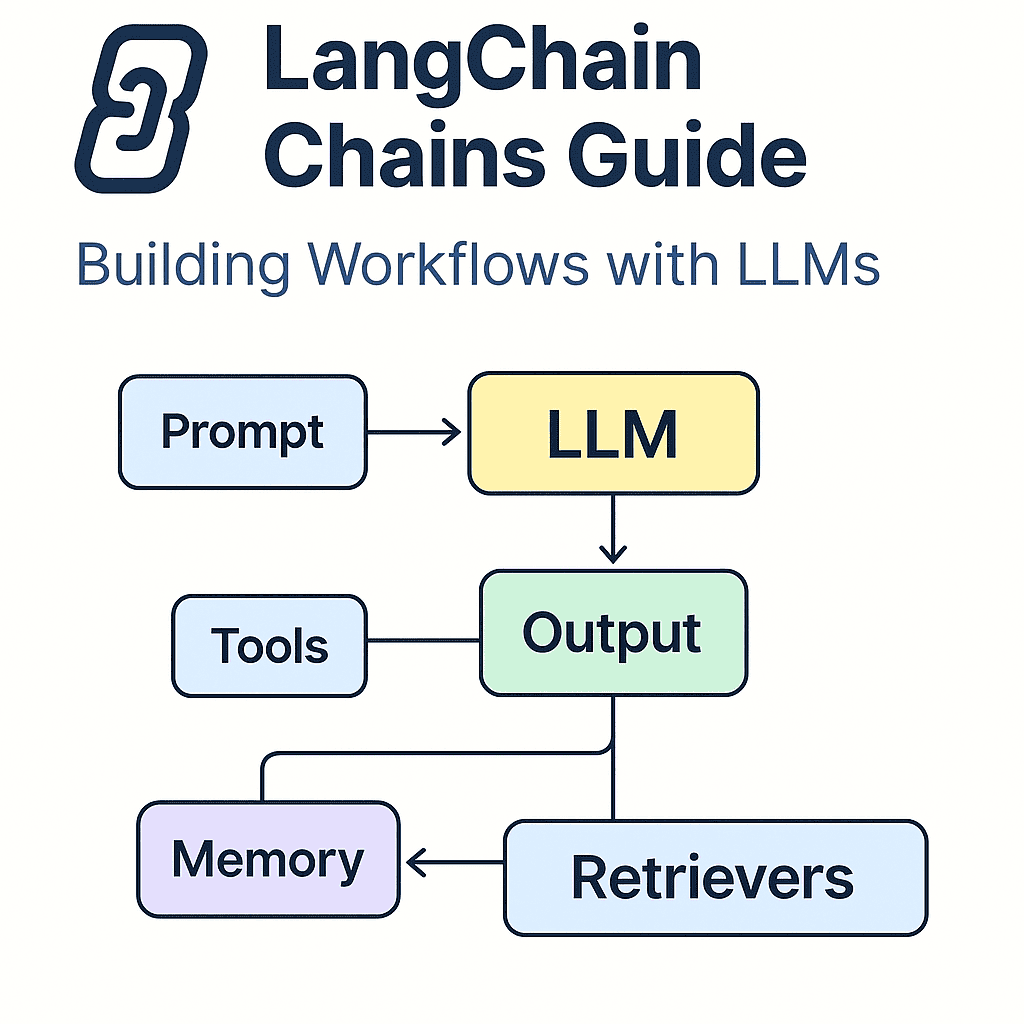
🔁 Retrieval-Augmented Generation (RAG)
RAG = Query → Retrieve → Generate
You retrieve relevant chunks from your vector store based on user input, then feed that context into an LLM to generate grounded, factual responses. Common RAG flow:
- Load documents
- Split into chunks
- Embed + store in vector DB
- Query vector store
- Inject retrieved context into LLM prompt
🧪 Example: Load Documents + Store in FAISS
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
# 1. Load the document
loader = PyPDFLoader("sample.pdf")
documents = loader.load()
# 2. Split into chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(documents)
# 3. Embed and store in FAISS
embedding = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(chunks, embedding)
# 4. Save locally (optional)
vectorstore.save_local("faiss_index")This example shows how to prepare documents for a Retrieval-Augmented Generation (RAG) setup.
✅ Use Cases
Below are some famous usecases:
- Internal knowledge bots
- Legal document assistants
- Financial report summarization
- Q&A over policy documents or handbooks
- YouTube or podcast summarizers
📦 LangChain Integrations
LangChain supports loading documents from:
- PyPDFLoader, UnstructuredPDFLoader
- WebBaseLoader, NotionDBLoader, YouTubeLoader
- DirectoryLoader to bulk load files
You can then use:
- FAISS or Chroma for local indexing
- RetrievalQAChain to tie everything together with an LLM
🔗 Related Blogs
TL;DR
- Document loaders turn files into retrievable chunks
- Vector stores let you semantically search those chunks
- Together, they enable powerful RAG apps grounded in your data
LangChain makes it easy to go from unstructured documents to searchable, LLM-augmented assistants.
Related Reading
Enterprise AI Architecture
Want more enterprise AI architecture breakdowns?
Subscribe to SuperML.