Pinecone Nexus and Context Compilation: RAG at Agent Scale
Pinecone's pivot from vector database to 'knowledge engine' exposes a structural flaw in how enterprise teams built their RAG stacks — and signals a new architecture layer between raw data and agent runtime that will reshape how production AI systems are designed.

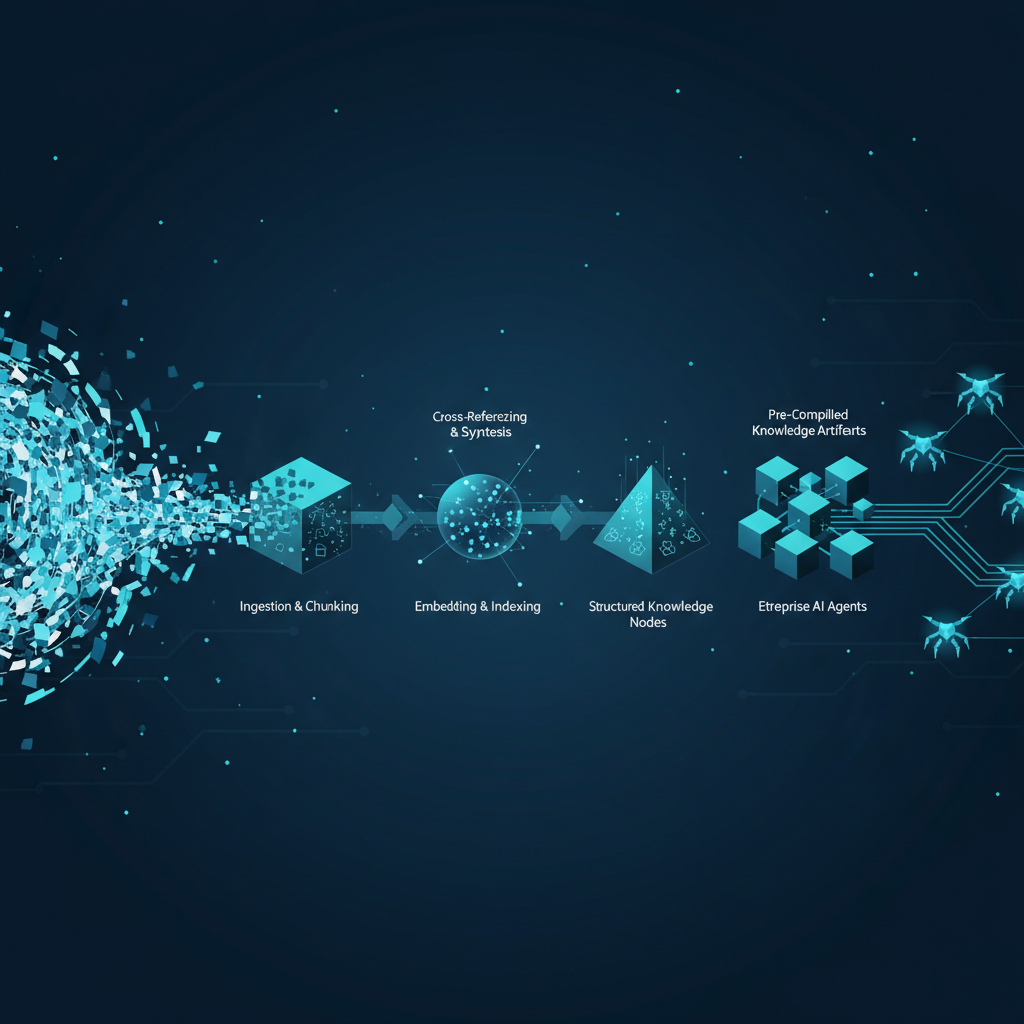
Table of Contents
Context Compilation Patterns for Agentic RAG Architectures
Learn how context compilation changes retrieval architecture at agent scale and how to design for latency, grounding quality, and control-plane observability.
Most enterprise AI architects who lived through the 2024–2025 RAG build-out remember the optimism. You chunked your documents, embedded them into a vector store, wired up a retrieval pipeline, and watched your LLM suddenly sound like it had read the company wiki. It felt like infrastructure. Repeatable. Scalable. Solved.
That architecture — build your retrieval stack, query at runtime, stuff context into a prompt — is now running at scale in hundreds of enterprises. And it is quietly failing in a way that the benchmarks never predicted: not catastrophically, not with stack traces, but with agents that spend 85% of their cycles doing retrieval work and still only complete tasks correctly about half the time. Task completion rates of 50–60% are not a configuration problem. They are an architectural ceiling.
Pinecone — the company that arguably did more than anyone to make retrieval-augmented generation mainstream — shipped something this week that amounts to an admission of that ceiling. Pinecone Nexus is not a better vector database. It is a fundamentally different layer in the stack, positioned between raw data and agent runtime, that shifts the expensive knowledge-structuring work from query time to compile time. The company is calling it a “knowledge engine.” What it actually is, is a signal that the RAG era for agentic AI is closing — and that teams who built retrieval-first architectures in 2025 are now carrying technical debt they probably haven’t priced into their roadmaps.
What Pinecone Actually Shipped
Nexus has two meaningful components worth understanding on their technical merits before getting to the vendor narrative.
The first is the context compiler. You give it raw source data — documents, APIs, structured records, whatever your data estate looks like — along with a task specification: what this agent is actually trying to do. The compiler outputs task-optimized knowledge artifacts. These are not generic embeddings. They are structured representations tuned to a specific agent’s reasoning requirements, built once at compile time. A sales agent working against the same underlying CRM data as a finance agent gets a completely different artifact optimized for deal-context synthesis rather than revenue reconciliation. The data estate stays unified; the knowledge representation gets differentiated by use case.
The second is KnowQL, which Pinecone is positioning as the first declarative query language designed for agents rather than humans. It exposes six primitives: intent, filter, provenance, output shape, confidence, and budget. The budget primitive is the one worth paying attention to — agents can specify latency and token cost envelopes in the query itself, which means the retrieval layer becomes cost-aware rather than just accuracy-aware.
The performance numbers Pinecone is publishing are aggressive. Internally benchmarked against traditional RAG, Nexus reportedly delivered 90% less token spend, task completion rates above 90% (up from the 50–60% range they measured in RAG-based systems), and 30x faster time-to-completion. They also compared it against Anthropic’s model context protocol in a financial analysis task: a workflow that consumed 2.8 million tokens via MCP was completed with 4,000 tokens via Nexus. That is a 99.86% reduction if the number holds — and that “if” is doing serious load-bearing work here, since Pinecone has not released these benchmarks for independent third-party validation.
The Architecture Problem Nexus Is Actually Solving
To understand why this matters for production systems, you need to be honest about what traditional RAG was actually optimized for. The classic retrieve-then-generate pattern was designed around a document question-answering use case: user asks a question, system finds relevant chunks, LLM synthesizes an answer. That’s a single-turn, single-task retrieval pattern. It works well.
Agentic workflows are structurally different. An agent is not running one query. It is executing a plan that may involve dozens of retrieval calls across a session, building state, backtracking, forming sub-queries it didn’t know it needed at the start. Every one of those calls hits the retrieval pipeline. Every one of them has to search the same undifferentiated corpus, rerank, assemble context, and handle the ambiguity of what the agent actually needs at that moment in the task. Multiply that by the token cost of passing that assembled context into a frontier model’s context window, and you start to understand why 85% of agent runtime ends up in retrieval overhead.
Traditional RAG was also designed with humans in the retrieval loop — implicitly. When a human sends a query, they tolerate some retrieval imprecision because they’re going to read the answer and judge it. Agents don’t have that tolerance. An agent that retrieves the wrong context at step three of a twelve-step workflow doesn’t error out — it continues confidently in the wrong direction, often completing all twelve steps incorrectly. The failure mode is silent and expensive.
Context compilation is an attempt to solve this by moving the knowledge structuring work offline. Instead of figuring out what context an agent needs at query time under latency pressure, you do that work once, at compile time, with full access to the task specification and no latency constraint. The resulting artifact is pre-structured for the agent’s reasoning requirements. This trades storage for compute at runtime, which is the right trade when your agents are doing high-volume, repetitive workflows against known task types.
The SuperML Take
Here is what this announcement actually signals versus what the press release version says.
The press release version is: Pinecone launched a new product that improves agent performance by 90% on tokens and gets task completion rates above 90%. That is impressive if the benchmarks validate.
The production version of this story is more interesting and more uncomfortable for a lot of enterprise AI teams. If context compilation is genuinely the right architecture for agentic AI, it means the retrieval stack you built in 2024–2025 has a structural design flaw — not a bug you can patch, but an architectural assumption that was correct for the use case you had and wrong for the use case you’re building toward. That’s a serious planning problem.
The claim that one financial analysis task went from 2.8 million tokens to 4,000 is not primarily a performance story. It is a cost structure story. At current frontier model pricing, 2.8 million tokens for a single workflow task is not a batch job cost — it is a unit economics problem that makes many agentic workflows commercially unviable at scale. If compilation-stage knowledge dramatically cuts per-task token consumption, it changes the business case for deploying agents at enterprise volume. That is the conversation that CTOs and platform architects should be having, not “is the benchmark methodology sound?” (even though that question also matters).
The KnowQL primitives, particularly the budget primitive, represent something genuinely new in retrieval system design: a query language that allows agents to express cost and latency constraints as first-class query parameters. This matters because it begins to make the retrieval layer legible to agent orchestrators that need to reason about compute budgets. Traditional vector search has no native concept of “answer me accurately within 200ms and under 10,000 tokens.” KnowQL tries to add that. Whether it becomes a standard or a proprietary lock-in play is the question to watch over the next eighteen months.
The scepticism that needs to be baked in: Pinecone’s benchmarks are self-reported and have not been independently reproduced. The 30x time-to-completion and 90% token reduction figures are from Pinecone’s internal testing. The architecture is novel enough that it needs to be validated across diverse enterprise data estates, task types, and agent frameworks before those numbers should factor into architecture decisions. Early enterprise adopters using Box as the data layer (Box announced a partnership with Nexus) are going to generate the first real-world signal. Watch for independent analysis from LangSmith, Arize, or Weights & Biases users who instrument Nexus in production — that data will be more reliable than the launch benchmarks.
Architecture Impact
What changes in system design?
The context compilation model introduces a new offline processing stage between the data layer and the agent runtime — similar conceptually to how compilers insert a build step between source code and execution. This means agent knowledge pipelines now have a bifurcated lifecycle: a compile phase (offline, data-intensive, run when underlying data or task specs change) and a retrieval phase (online, fast, against pre-structured artifacts). Teams need to design triggering and versioning systems for knowledge artifact compilation, not just for model updates. Data freshness guarantees change significantly — you are now managing artifact staleness, not just index staleness.
What new failure mode appears?
The compile-time architecture introduces knowledge artifact staleness as a new class of production failure. In traditional RAG, stale data in your vector index is a known, observable failure — retrieval returns outdated chunks and you can detect this with freshness monitoring. With pre-compiled artifacts, staleness is more insidious: the artifact was correct when compiled, the retrieval is accurate against the artifact, and the agent completes the task confidently — against knowledge that no longer reflects ground truth. In fast-moving domains like financial data, product catalogs, or compliance documentation, an artifact compilation pipeline that doesn’t track source data change rates at granular level will silently serve agents accurate-looking but stale knowledge. This is a new failure mode that existing observability tooling is not instrumented to catch.
What enterprise teams should evaluate:
- AI Platform / MLOps engineers: How do you trigger artifact recompilation when source data changes? What’s the SLA for artifact freshness, and does it align with your data update rates? You need a new pipeline stage, not just a new query endpoint.
- AI Architects / System Designers: Does compilation-stage knowledge make sense for your task mix? High-volume, task-repeatable workflows (document classification, contract review, financial analysis) are strong candidates. Ad-hoc exploratory agents with unpredictable task specifications are poor candidates — the compilation model requires you to know the task type in advance.
- Security and Compliance teams: Pre-compiled knowledge artifacts need to carry data lineage and access control metadata from source to artifact to query result. The provenance primitive in KnowQL is designed for this, but audit trail completeness for regulated industries (SR 11-7, EU AI Act Article 13) needs validation before deployment in model risk environments.
Cost / latency / governance / reliability implications:
The token reduction claims — if independently validated in production — represent a genuine structural change in agentic AI economics. At $15–30 per million tokens for frontier models, cutting per-task consumption by 90% can move workflows from commercially marginal to viable at enterprise volume. Latency implications cut both ways: artifact retrieval at runtime should be faster than full-corpus search and reranking, but compile time adds an offline processing delay that must be factored into data freshness SLAs. Governance teams need to evaluate whether KnowQL’s provenance primitive satisfies existing model risk documentation requirements, particularly for workflows touching credit decisions, AML screening, or regulatory reporting — compilation-stage knowledge adds a layer of indirection that may require new audit documentation.
What to Watch
The independent benchmark data matters most right now. Pinecone’s internal numbers are directionally interesting but need third-party validation in production environments with real enterprise data estates. The first signal will likely come from Box customers using the joint integration — watch for case studies from financial services or legal firms in Q3 2026, which are the verticals most likely to push agentic workflows at high volume.
KnowQL’s adoption outside the Pinecone ecosystem is the long-term indicator of whether this is architecture or lock-in. If the query language gets adopted by LangGraph, Semantic Kernel, or LlamaIndex as a standard interface, it matters. If it stays Pinecone-proprietary, it becomes a build-vs-buy decision with real switching cost implications.
The companies most exposed by this architectural shift are those who invested heavily in custom RAG orchestration layers in 2024–2025. If context compilation becomes standard practice for agentic workflows, that orchestration layer built around runtime retrieval becomes a maintenance burden rather than a competitive advantage. The engineering teams who wrote it will not want to hear that, and the platform architects who approved the investment will want to see the independent benchmarks before making any architectural pivot decisions.
Finally, watch what Weaviate, Qdrant (fresh off a $50M Series B), and Chroma do in response. Pinecone is not the only company that needs a strategic answer to the question of what vector search looks like in an agentic world. Their architectural responses over the next two quarters will tell you whether context compilation is a genuine paradigm shift or a Pinecone-specific positioning move.
Related Reading
- OpenAI and Anthropic Adopted the Palantir Playbook. Now Enterprise Architecture Teams Need a Counter-Move.
- Five AI Vendors Shipped Agent Registries in One Quarter — That’s Not Competition, It’s a Production Crisis Signal
- Cerebras Files for $26.6B IPO With OpenAI as 86% of the Backlog: The Wafer-Scale Tier Just Became an Architecture Decision
Sources
- Pinecone Nexus: The Knowledge Engine for Agents (Pinecone Blog)
- Better Models Won’t Save Your Agent (Pinecone Blog)
- The RAG era is ending for agentic AI — a new compilation-stage knowledge layer is what comes next (VentureBeat)
- Enterprise RAG rebuild: hybrid retrieval adoption tripled in Q1 2026 (VentureBeat)
- Pinecone providing compiled vector artifacts to accelerate AI Agents (Blocks & Files)
- The company that made RAG mainstream is now betting against it (The New Stack)
- Pinecone targets agentic completion rates (Enterprise Times)
Enterprise AI Architecture
Want more enterprise AI architecture breakdowns?
Subscribe to SuperML.