Ontology: The Missing Semantic Layer That Makes Enterprise AI Actually Work
Everyone's deploying AI, but most enterprise systems are reasoning over raw data with no shared understanding of what that data means. Ontologies fix that — and Palantir built an entire $50B platform on this idea. Here's what you need to know.


Table of Contents
Ask a senior engineer what makes an enterprise AI system fail in production and you’ll get a dozen answers: latency, hallucinations, context limits, tool call reliability, cost. But ask the same question of the people who’ve watched the most enterprise AI programs actually collapse — and a different answer surfaces more often than any of the above.
The system didn’t know what anything meant.
An LLM can generate SQL from natural language. It can summarize a document, draft a response, write code. What it cannot do, without additional infrastructure, is reliably answer the question “what is a customer in this system?” — and have that answer be consistent across the credit model, the fraud engine, the CRM integration, the compliance report, and the AI agent that’s supposed to weave all of them together. In an enterprise with twenty years of data history and forty systems of record, “customer” might mean a legal entity, a household, an individual, a relationship, or a counterparty, depending on which database you’re querying and which decade the schema was designed.
That disambiguation problem — knowing what things are and how they relate to each other — is exactly what an ontology solves. And understanding it is increasingly the difference between an enterprise AI that runs confidently in demos and one that runs reliably in production.
What Is an Ontology?
The word “ontology” comes from philosophy — it’s the branch of metaphysics concerned with the nature of being: what things exist, what categories they fall into, how they relate to one another. Aristotle wrote about it. Heidegger built a career on it. And in the 1990s, computer scientists borrowed the word for a precise technical purpose: to describe formal, machine-readable representations of a domain’s concepts and the relationships between them.
In computer science and AI, an ontology is a formal specification of a shared conceptualization. That definition is more powerful than it sounds. Break it down:
Formal: It’s written in a logic-based language with precise, unambiguous semantics. Not natural language. Not a schema diagram. A machine can reason over it.
Specification: It explicitly defines the vocabulary — the classes, properties, relationships, and constraints — for a domain.
Shared: It’s a contract between systems. When an ontology says “a Customer is a type of Party that has at least one Account,” every system that adopts that ontology agrees on those semantics. There’s no ambiguity across service boundaries.
Conceptualization: It models concepts — the real-world entities and relationships we care about — not just data structures. The difference matters enormously for AI.
The standard technology stack for ontologies in the web and enterprise world is built on W3C standards: RDF (Resource Description Framework) as the data model, OWL (Web Ontology Language) for expressing richer semantics and reasoning rules, and SPARQL as the query language. Together these form what’s sometimes called the Semantic Web stack — a set of technologies that never fully delivered on its 2000s promise as a web-wide knowledge layer, but which quietly became foundational infrastructure for enterprise knowledge management and, increasingly, enterprise AI.
The practical mental model: an ontology is a typed, constrained knowledge graph where the nodes are instances of real-world entities and the edges are typed relationships between them — and where the schema itself encodes business rules, reasoning constraints, and conceptual hierarchies.
The Layer Cake: Where Ontology Fits in an AI System
To understand why ontologies matter for AI, it helps to think about the layers of a production AI system from the bottom up.
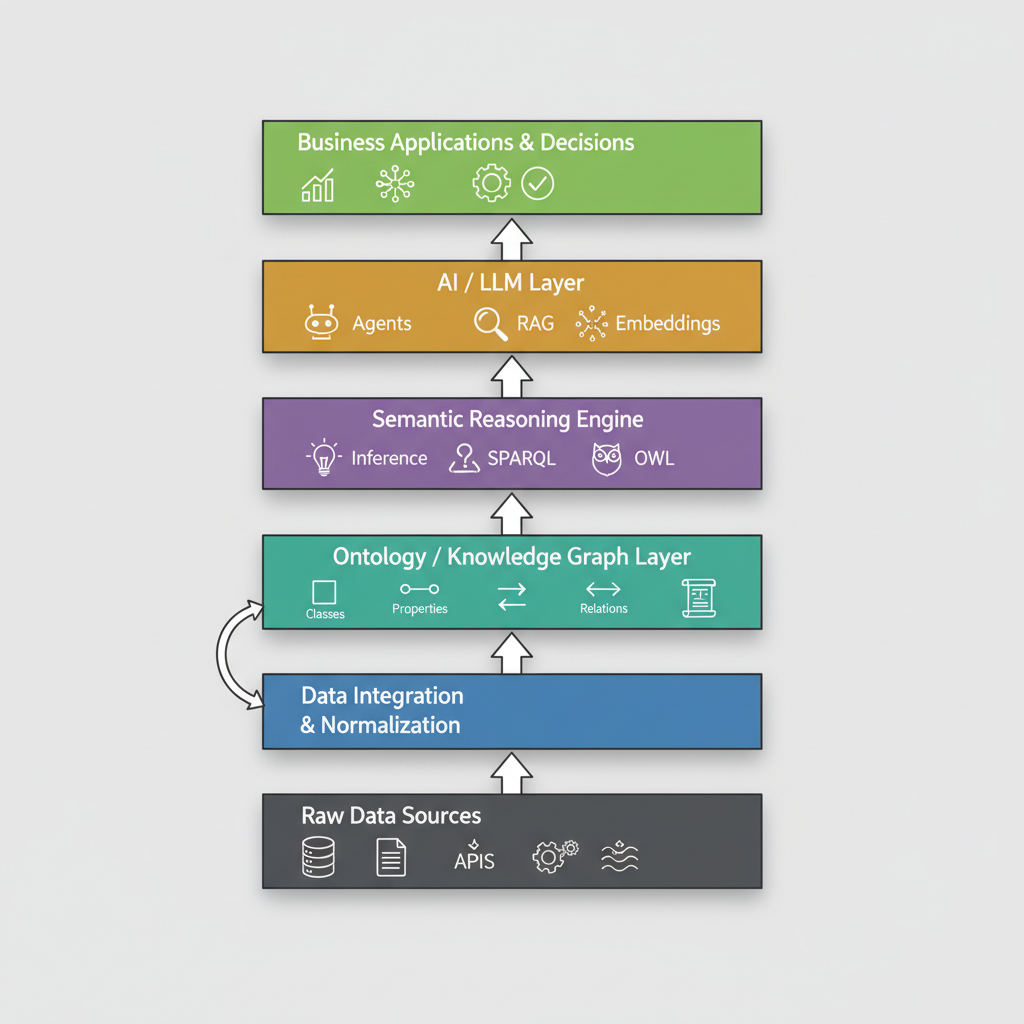
At the bottom you have raw data sources — databases, APIs, event streams, files. This is the layer most data engineering teams live in. It’s where the tables are, where the schemas are, where the pipelines run. It’s also the layer where your “customer” is stored as cust_id in one table and customer_uuid in another, linked by a join that someone wrote in 2017 and which nobody fully trusts anymore.
Above that sits data integration and normalization — ETL, CDC, the whole apparatus of getting data into a shape that downstream systems can use. This layer resolves physical format differences. It doesn’t resolve semantic differences.
The ontology layer is where semantic resolution happens. This is where “customer” becomes a first-class entity with defined properties, defined relationships to accounts and transactions and addresses, and defined rules about what constitutes a valid customer record. The ontology is the semantic contract of the enterprise — the layer that says “here is what things are, here is how they relate, here is what you can infer from that relationship.”
Above the ontology sits the semantic reasoning engine — a system that can traverse the knowledge graph, infer implicit relationships, execute SPARQL queries, and apply OWL rules to derive new facts from existing ones. This is where “if a Customer has a high-risk Transaction and the Transaction counterparty is a sanctioned entity, then flag the Customer for review” becomes a machine-executable rule rather than a comment in someone’s spreadsheet.
Then comes the AI / LLM layer — your embeddings, your vector search, your language models, your agent orchestration. This is where the generation happens. And the critical architectural insight is that this layer is downstream of the ontology. The LLM doesn’t decide what a customer is. The ontology does. The LLM’s job is to reason over and communicate the results, not to make up the semantics.
At the top: business applications and decisions — dashboards, agent workflows, automated alerts, compliance reports. The things your users actually see.
Most enterprise AI teams today skip the ontology layer entirely. They connect the LLM layer directly to the raw data layer — or at best to the normalized data layer — and then wonder why their agents hallucinate business logic and their RAG system returns confidently wrong answers.
Why Ontologies Are Non-Negotiable for Production AI
The gap between the demo and production for enterprise AI is almost always a semantic gap. Let me make this concrete with three failure modes that ontologies directly address.
Ambiguity collapse. When your RAG system retrieves documents to answer a question about “account closure procedures,” it retrieves based on semantic similarity of embeddings. If your enterprise uses “account” to mean checking accounts in one system, trading accounts in another, and AWS accounts in a third, your vector search has no way to disambiguate. It retrieves everything that matches “account closure” and hands it to the LLM as context. The LLM combines procedures from three unrelated systems into a confidently hallucinated answer. An ontology-grounded system resolves “account” to a typed entity before retrieval, constraining the search to the domain relevant to the question.
Inference blindness. A plain LLM can answer “what transactions did customer X make?” if you give it the right tables. It cannot answer “what transactions is customer X’s household exposed to through shared beneficial ownership across counterparties subject to OFAC sanctions?” — not because the LLM lacks intelligence, but because that answer requires traversing a typed relationship graph with specific semantic rules. That’s exactly what an ontology + reasoning engine is built for.
Policy groundlessness. Enterprise AI systems need to be auditable. When an underwriting model declines a loan, a regulator wants to know why — not in natural language generated by an LLM, but in traceable logic with citations. An ontology provides the semantic structure that makes AI decisions interpretable: the decision was made because this applicant is classified as an entity of this type, with these properties, which trigger this rule, which produces this outcome. Without the ontology layer, you have a black box with a natural language rationalization on top.
Palantir’s Bet: Making the Ontology Operational
Palantir Technologies has been building on the ontology concept longer than almost any enterprise software company. Their insight, articulated clearly in Palantir Foundry’s design philosophy, is that the ontology isn’t just an analytical metadata layer — it’s the operational core of the enterprise.
The Palantir Ontology is described, in their own documentation, as a digital twin of the organization. Not “digital twin” in the narrow IoT sense of mirroring a physical asset, but in the broader sense of providing a complete, semantically coherent model of the enterprise’s entities, relationships, and operations — one that both reads from and writes back to reality.
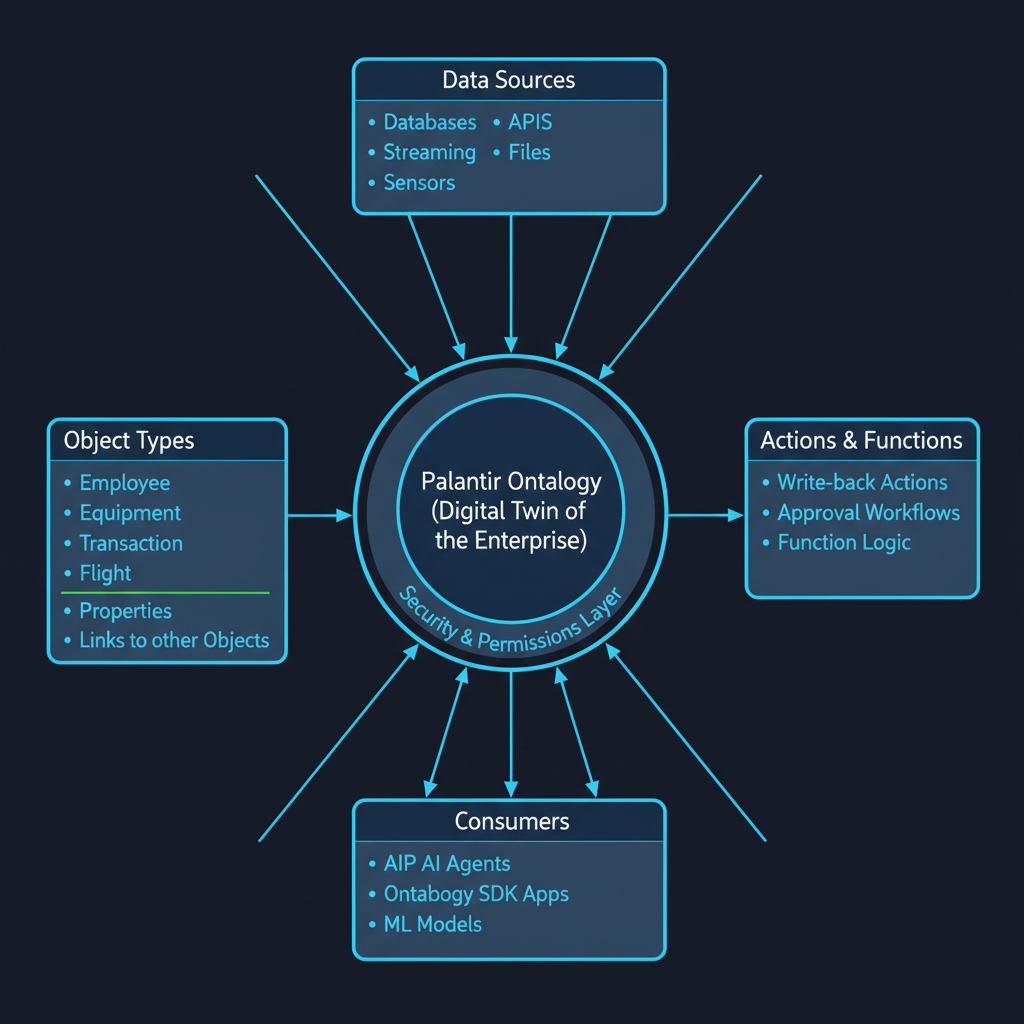
The architecture has three conceptual layers that Palantir calls semantic, kinetic, and dynamic.
The semantic layer is the knowledge model: Object Types (classes of real-world entities — Employee, Equipment, Transaction, Flight, Patient), Properties (attributes of those objects), and Links (typed relationships between objects). This is your ontology in the classical sense. A Transaction has a currency, an amount, a timestamp, and is linked to a Customer and a CounterpartyAccount. These definitions are stored once, centrally, and every downstream application reads from the same model.
The kinetic layer is where Palantir gets genuinely interesting: Actions and Functions. Actions are structured write-back operations — governed, auditable ways to modify the state of Ontology objects. Functions are code-based logic that takes objects as inputs and returns outputs. The kinetic layer is what makes the Palantir Ontology different from a traditional knowledge graph: it’s not read-only analysis. It’s a live operational layer that governs how the enterprise acts on its data. When a fraud analyst reviews a flagged transaction and marks it as confirmed fraud, that action flows through the Ontology as a governed, permissioned write-back. The audit trail is built in.
The dynamic layer handles security and permissions — fine-grained, object-level access control that respects the semantic relationships in the model. You don’t just have table-level permissions; you have semantic permissions. A user who can see Customer objects in Region A cannot see Customer objects in Region B, even if those objects live in the same underlying dataset.
The result is that every downstream system — dashboards, ML models, AI agents, external applications built with the Ontology SDK — reads from and writes to the same semantic model. There’s no “which database is the source of truth?” problem, because the Ontology is the source of truth for meaning, not just storage.
AIP: When You Plug AI Into the Ontology
Palantir’s AIP (Artificial Intelligence Platform) is the layer built on top of the Ontology for the generative AI era. The key architectural decision: AIP agents are natively ontology-aware. They don’t query raw databases; they query Object Types. They don’t take arbitrary actions; they invoke governed Actions. They don’t produce unauditable outputs; they produce outputs that flow through the Ontology’s audit trail.
This is a fundamentally different architecture from most enterprise LLM deployments, where the LLM is given a pile of context — some documents, some database results — and asked to produce an answer. In that architecture, the LLM is making semantic decisions: it’s deciding what “customer” means in this context, whether a transaction from subsidiary X should count toward the exposure of parent company Y, whether the policy document retrieved applies to the product type in question. These are decisions that belong in the semantic layer, not in the language model.
When you connect an AIP agent to a Palantir Ontology, the agent can ask “show me all high-risk transactions linked to Customer X’s household” and the query resolves through the semantic graph — traversing the household link, applying the risk classification rules, returning a typed, bounded result set. The LLM’s job is then to reason about and communicate that result, not to construct it. The Ontology SDK lets external developers build applications that tap into this semantic model with type-safe, code-first APIs — the semantics of the enterprise exposed as a developer interface.
Ontology-Grounded RAG vs. Plain RAG
For teams not building on Palantir, the most immediate application of ontology thinking is in RAG architecture. The difference between ontology-grounded retrieval and plain vector search is not cosmetic.
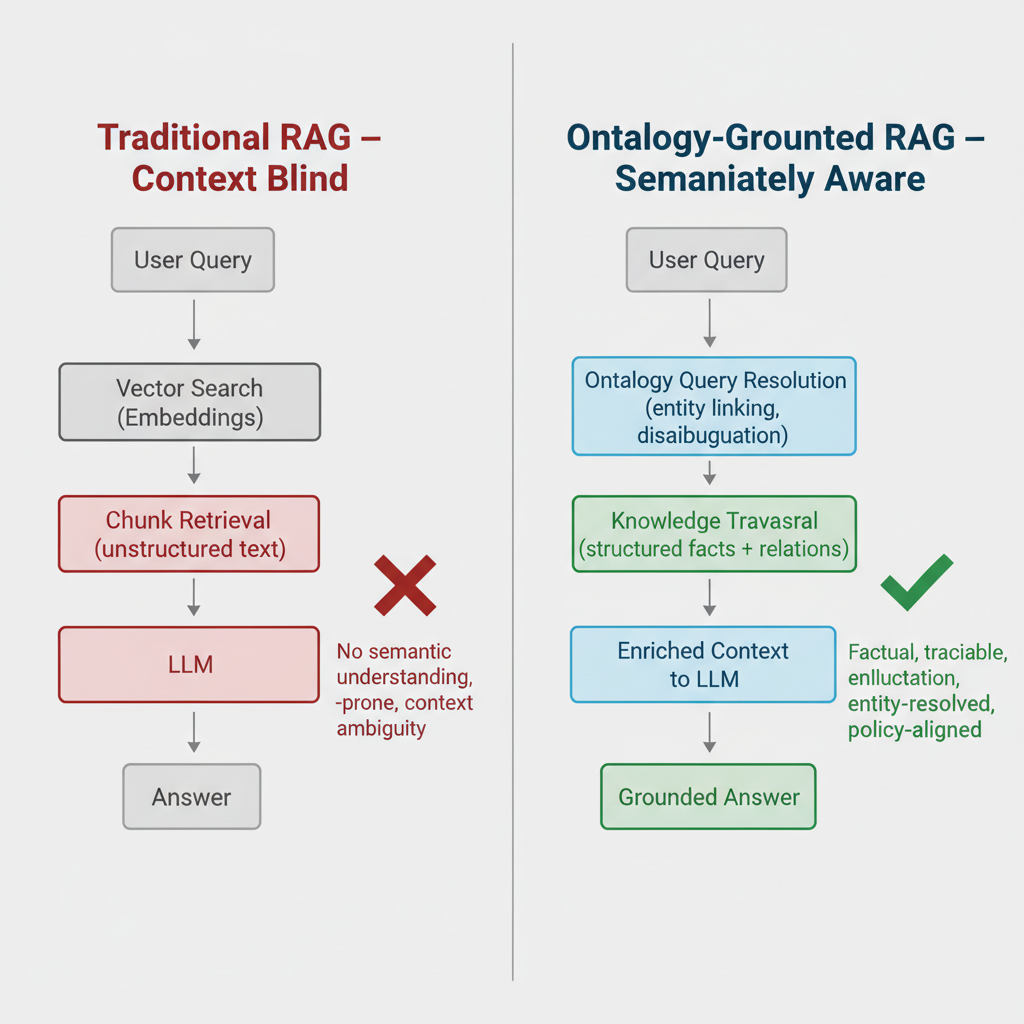
In plain vector RAG, a user query is embedded, compared against document embeddings, and the top-k most similar chunks are retrieved and passed to the LLM as context. The system has no semantic understanding of the query or the documents — it’s working purely on distributional similarity. This works reasonably well for many tasks and fails badly for others, specifically the tasks where the answer requires understanding entity identity, typed relationships, or domain-specific rules.
In ontology-grounded RAG, the query processing starts with an entity resolution step. Before any vector search, the system attempts to identify what entities the query is about (using the ontology’s class hierarchy and property definitions), what relationships between them are being asked about, and what policy or logic constraints are relevant. The retrieval is then constrained to semantically relevant entities and their linked documents — and the context passed to the LLM is enriched with structured facts from the knowledge graph, not just raw text chunks.
The results are significantly better for enterprise use cases. A financial analyst asking about a client’s exposure to a specific sector gets back structured data about the relevant positions, not a mix of similar-sounding paragraphs from unrelated reports. A compliance officer asking about a counterparty’s sanctions history gets back a traceable fact set derived from structured records, not a semantically similar chunk that happens to mention “sanctions” in a different context.
Google, Microsoft, and a cohort of specialized vendors are all building toward this architecture. Google’s Knowledge Graph and Enterprise Knowledge Catalog, Microsoft’s Fabric IQ semantic layer, and offerings from Timbr.ai, data.world, and Oxford Semantic Technologies are all variations on the same thesis: structured semantic meaning is the missing layer that makes enterprise AI reliable.
Building Ontologies: What It Actually Takes
If you’re now convinced that ontologies are important and wondering why more enterprises haven’t built them, here’s the honest answer: ontology engineering is hard, slow, and requires domain expertise that’s genuinely rare.
Building a useful enterprise ontology requires bridging three disciplines that rarely coexist in one team: domain knowledge (what do the business concepts actually mean?), logical formalization (how do you express those meanings in OWL/RDF with correct semantics?), and data engineering (how do you map the formal ontology to the messy reality of your actual data?). Getting one of these wrong produces an ontology that either doesn’t reflect reality, doesn’t reason correctly, or can’t be populated with real data.
The typical failure mode is overengineering. Teams try to model the entire enterprise in a single ontology, get bogged down in definitional debates that have no right answer, and deliver nothing. The successful pattern is starting narrow: pick one high-value domain (fraud cases and counterparties, or loan applications and applicants, or equipment and maintenance events), build a precise ontology for that domain, validate it against real data, and expand incrementally. The goal is to demonstrate that ontology-grounded AI outperforms flat-data AI on a measurable use case — then use that win to fund the next domain.
The tooling has improved substantially. Protégé remains the open standard for OWL ontology editing. GraphDB, Stardog, Neptune, and Virtuoso are mature enterprise triple stores. Python’s Owlready2 and the RDFLib ecosystem make integration into data science pipelines tractable. And an emerging generation of LLM-assisted ontology construction tools can bootstrap initial class hierarchies from natural language documentation — dramatically reducing the most tedious part of the engineering work.
The SuperML Take
The enterprise AI race of 2024–2025 was won on deployment velocity. Teams that moved fast, got models in front of users, and shipped workflows ahead of the field captured the early credibility and budget. That phase is largely over. The race of 2026–2027 will be won on reliability, auditability, and the ability to build AI systems that actually understand the business they’re operating in.
Ontologies are the enabling infrastructure for that second phase. Not because they’re intellectually interesting (they are), and not because they’re a regulatory requirement (they will be), but because the failure modes of ontology-free AI at enterprise scale are increasingly visible and increasingly expensive. When your AI agent confidently executes the wrong policy because it mapped “customer” to the wrong class, or when your RAG system gives a compliance officer a hallucinated sanction status on a counterparty, the cost is not an engineering post-mortem — it’s a regulatory conversation.
Palantir’s commercial success is, in part, a proof of concept for the ontology-first architecture. The company’s client base — defense agencies, major banks, healthcare systems, national governments — operates in environments where being wrong has severe consequences. Palantir’s answer to that challenge was to build the semantics of the operation into the platform before building the intelligence on top. The Ontology is not a feature of Palantir Foundry; it’s the foundational design decision. Everything else — ML pipelines, dashboards, AIP agents, the Ontology SDK — is downstream of that choice.
The critique of Palantir’s approach is real: proprietary ontology locked inside a vendor platform creates significant switching costs, and the Palantir Foundry stack requires substantial commitment. But the critique doesn’t invalidate the underlying architectural insight. The insight is correct — you need a semantic layer. The question is whether you build it proprietary, open-standard, or through one of the emerging hybrid platforms trying to thread that needle.
For teams not running on Palantir, the practical path forward is to treat ontology-building as a first-class engineering investment, not a future nice-to-have. Start with the entities your AI agents care about most. Define them precisely. Map them to your data. Build the reasoning layer. Then connect your LLMs. The teams that do this first will have AI systems that get more reliable as they scale. The teams that skip it will find that their agents get more confident and more wrong at the same rate.
Architecture Impact
What changes in system design? Adding an ontology layer means splitting your AI system’s semantic concerns from its computational concerns. The LLM should receive typed, entity-resolved, semantically enriched context — not raw table dumps. This requires a new architectural component between your data stores and your AI layer: an ontology manager that handles entity resolution, graph traversal, and structured context construction. For agent architectures, tool definitions need to align with ontology-defined actions rather than ad-hoc API calls.
What new failure mode appears? The critical failure mode is ontology drift — the semantic model becomes stale relative to the business reality it represents. If the ontology defines “high-value customer” with a threshold set in 2022, and the business changed that threshold in 2024 without updating the ontology, every downstream AI system is reasoning from an incorrect definition. Unlike data freshness, ontology staleness is invisible to standard monitoring. It requires active stewardship: regular reviews of class definitions, property constraints, and inference rules against current business policy.
What enterprise teams should evaluate:
- Data Architecture teams: Audit the semantic boundary between your raw data layer and your AI layer — are LLMs receiving typed, entity-resolved context or raw joins? The answer determines where ontology investment will have the highest ROI.
- AI/ML Engineering: Evaluate RAG retrieval quality on entity-intensive queries; if accuracy degrades when queries involve multiple business concepts or typed relationships, an ontology layer is the structural fix.
- Compliance & Risk teams: Assess whether current AI systems produce auditable, entity-traceable rationales for high-stakes decisions; if not, ontology grounding is the path to regulatory defensibility.
- Platform / Infrastructure teams: Evaluate triple store options (GraphDB, Neptune, Stardog) against your current graph or metadata infrastructure; most enterprises already have partial knowledge graph investments that can seed an ontology layer.
Cost / latency / governance / reliability implications: Initial ontology engineering for a single high-value domain typically runs $500K–$2M in engineering cost at larger institutions, with ongoing stewardship running 0.5–2 FTE depending on domain complexity. Query latency for ontology-grounded retrieval adds 50–200ms versus plain vector search, dominated by graph traversal depth rather than ontology complexity — acceptable for most enterprise workflows, potentially problematic for real-time trading or fraud decisioning where sub-100ms is required. The governance upside is substantial: ontology-grounded systems produce traceable, reproducible reasoning chains that satisfy both internal audit and emerging regulatory AI explainability requirements.
What to Watch
The enterprise ontology space is in an accelerating arms race. Palantir’s commercial momentum — its 2025 revenue growth and expanding enterprise client roster — has validated the ontology-first architecture in the market, and competitors are responding. Microsoft’s Fabric IQ semantic layer, Google’s Enterprise Knowledge Graph, and a cohort of specialized vendors including Timbr.ai, data.world, and Oxford Semantic Technologies are all building toward the same destination from different starting points.
Watch also for LLM-native ontology tools. Several research groups and startups are working on using LLMs themselves to accelerate ontology construction — bootstrapping class hierarchies from documentation, suggesting property definitions from schema analysis, identifying conflicts between existing definitions. If this tooling matures, the primary bottleneck for ontology adoption (engineering time) becomes substantially cheaper.
The regulatory driver will arrive. The EU AI Act’s explainability requirements, emerging SEC guidance on AI in financial reporting, and the Fed’s pending RFI on generative AI governance in banking all point in the same direction: AI systems that produce high-stakes decisions need traceable reasoning, and traceable reasoning is much easier to achieve when your system has a semantic model of the concepts it’s reasoning over. The enterprises that build that semantic infrastructure ahead of the regulatory requirement will have a significant compliance advantage over those that retrofit it under examiner pressure.
Related Reading
- The Ontology Layer Every Enterprise AI System Needs (But Almost None Have)
- The NL-2-SQL Agent Trap: Why LLMs Need an Ontology Layer to Stop Hallucinating Your Database
- When RAG Breaks at Agent Scale: Pinecone Nexus and the Context Compilation Turn in Enterprise AI
Sources
- Palantir Ontology — Official Platform Page
- Palantir Foundry Ontology Overview
- Palantir Ontology Core Concepts
- Understanding Palantir’s Ontology: Semantic, Kinetic, and Dynamic Layers — Medium
- AIP Architecture Overview — Palantir
- Ontology Engineering as the Semantic Operating System of the AI-First Enterprise — Medium
- Google vs Microsoft vs Palantir: The Enterprise Ontology Race — Medium
- Ontologies, Context Graphs, and Semantic Layers: What AI Actually Needs in 2026 — Metadata Weekly
- Unlocking the Power of Generative AI: Why OWL Leads in Knowledge Representation — data.world
- The Power of Ontology in Palantir Foundry — Cognizant
- What Is Knowledge-Based AI? What Can OWL Ontological Reasoning Do? — Oxford Semantic Technologies
- SR 11–7 to SR 26–2: From Checklist to Judgment in Model Risk Management — Medium
Enterprise AI Architecture
Want more enterprise AI architecture breakdowns?
Subscribe to SuperML.