The Hidden Bottleneck Inside Every LLM Inference Stack — and Why llm-d v0.7 Just Made Disaggregation an Enterprise Architecture Decision
llm-d v0.7 ships predicted-latency scheduling to GA and joins the CNCF — forcing enterprise AI teams to confront the structural ceiling of monolithic inference and treat LLM serving as a real distributed systems problem.

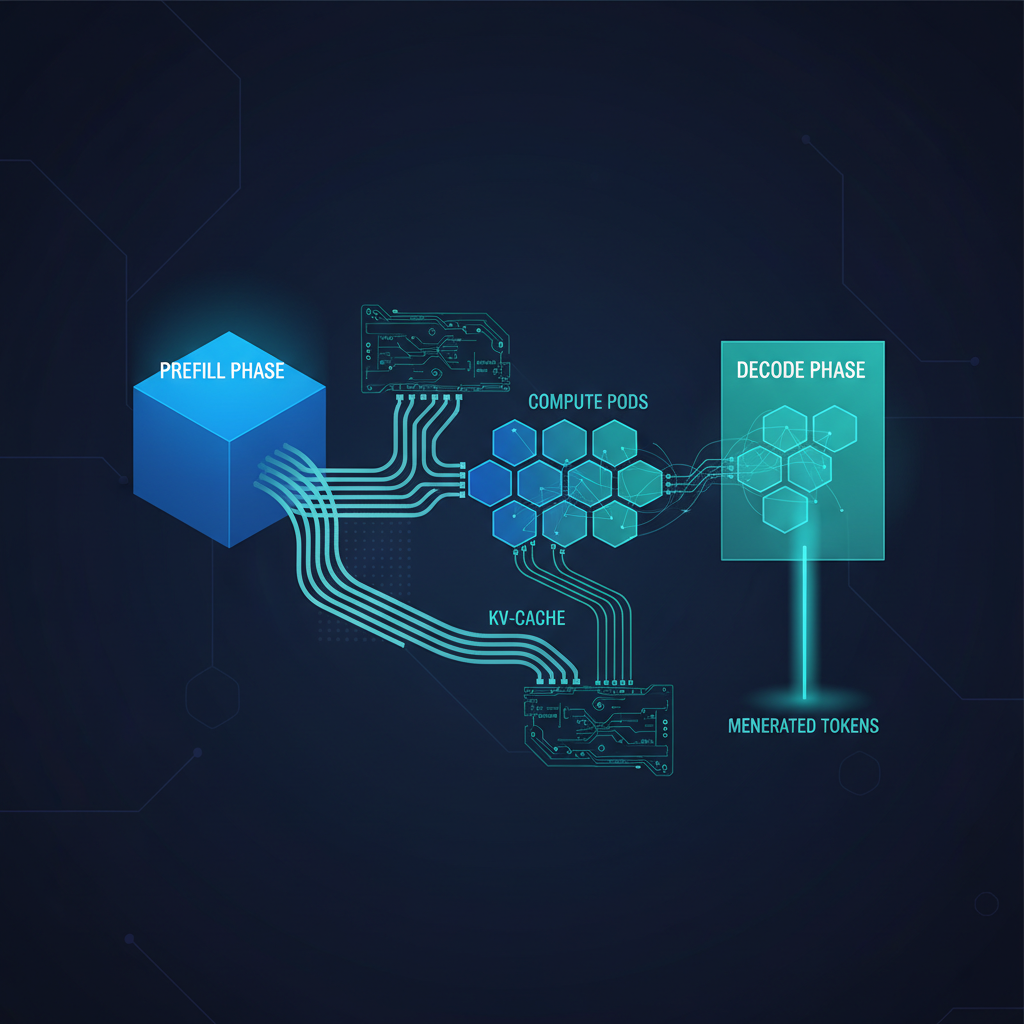
Table of Contents
There is a structural flaw in the way most enterprise AI teams run LLM inference, and it has nothing to do with the model. It has to do with the assumption baked into monolithic serving stacks — that prefill and decode are the same problem, running on the same hardware, governed by the same scheduler.
They are not. Prefill is a compute problem. It is dominated by arithmetic throughput: the GPU has to process a potentially large prompt in a single forward pass, maximizing FLOPs per second. Decode is a memory problem. It is dominated by bandwidth: the GPU streams a narrow sequence of tokens one at a time, with KV-cache reads gating every single step. On identical hardware, the two phases have fundamentally different bottlenecks. Running them together means one of them is always waiting on the other.
For most of 2024 and into 2025, the industry response to this was to throw more GPUs at the problem. If your monolithic vLLM instance was hitting latency SLOs, you added another replica. If your tail latency was exploding under load, you scaled horizontally. It worked — until it didn’t. As LLM-powered products scaled to millions of users, the economics broke down. Adding replicas doesn’t help when your bottleneck isn’t parallelism, it’s the structural mismatch between what the prefill phase needs and what the decode phase needs on the same pod.
Disaggregated inference — splitting prefill and decode into separately schedulable, separately scalable Kubernetes workloads — was the answer. And last week, llm-d v0.7 shipped predicted-latency scheduling to general availability, marking the moment this architectural pattern stopped being experimental research and became production-grade infrastructure.
What llm-d Actually Is — and Why the CNCF Matters
llm-d is not another inference framework. Frameworks — vLLM, SGLang, TGI — are what you use to load and serve a model on a GPU. llm-d sits one layer above that. It is a Kubernetes-native distributed scheduling and routing layer that takes your existing vLLM deployments and reorganizes them into a disaggregated topology with intelligent request routing.
The stack has three primary components. The inference gateway intercepts requests and routes them based on real-time state: KV-cache occupancy, pod load, request characteristics, and hardware type. Prefill pods run on compute-optimized hardware and handle the initial prompt processing — dense arithmetic, high FLOPs, short-lived per request. Decode pods run on memory-bandwidth-optimized hardware and handle token generation, streaming the KV-cache through HBM as efficiently as possible. The scheduler manages the handoff between them.
When llm-d joined the CNCF Sandbox in March 2026 — founded by Red Hat, Google Cloud, IBM Research, CoreWeave, and NVIDIA — it was the signal that this is no longer a one-vendor experiment. AMD, Cisco, Hugging Face, Intel, Lambda, Mistral AI, UC Berkeley, and University of Chicago are all contributors. The CNCF imprimatur means governance, a roadmap, multi-vendor CI, and a community that will outlast any single product cycle. It is the difference between adopting a framework because one company thinks it is a good idea and adopting an infrastructure standard because the cloud-native ecosystem converged on it.
v0.7: What Predicted-Latency Scheduling Actually Solves
The fundamental scheduling tension in disaggregated inference is a real-time optimization problem. Minimizing TTFT (time to first token) benefits from consolidating decode on pods that already have relevant KV-cache hits — prefix reuse makes the first token arrive faster. Minimizing TPOT (time per output token) benefits from spreading load to reduce batch size and keep each decode step quick. These two objectives pull in opposite directions, and the optimal balance shifts continuously as traffic arrives in patterns the scheduler has never seen before.
Previous versions of llm-d used heuristic scorers — active request count, cache hit rate, hardware affinity — to make routing decisions. v0.7’s predicted-latency scheduling replaces this with a learned model. The scheduler trains on the relationship between server state, request shape, and measured latency outcomes, then uses that model to predict the actual latency impact of routing each request to each available pod. Instead of optimizing for a proxy metric, it optimizes for the metric you actually care about.
This matters in practice because heuristic scorers break under distribution shift. If your traffic pattern changes — a new agent workflow generates longer prompts, a model update changes decode-phase memory footprint, a new product feature sends batches of short requests instead of individual long ones — your heuristics degrade silently. Predicted-latency scheduling adapts because it is continuously learning from actual outcomes. The failure mode is still there (distribution shift can outrun the model’s update cadence), but it is significantly more robust than static scoring.
The v0.7 release also ships an experimental batch gateway, expanded CI across OpenShift, GKE, and CoreWeave, and AMD ROCm, Intel Gaudi, and CPU/AMX support confirmed in v0.6. Red Hat AI 3.4, which shipped at Red Hat Summit in May, bundles llm-d as its default distributed inference layer — meaning any OpenShift deployment targeting enterprise AI workloads now has this available without additional installation.
The Enterprise Adoption Question Nobody Is Asking
The disaggregation architecture generates impressive benchmark numbers. IBM Research has validated approximately 3,100 tokens per second per B200 decode GPU, and 16×16 B200 prefill/decode topologies hitting over 50,000 output tokens per second. Those numbers are real, but they are not the question enterprise teams should be asking first.
The question is: at what scale does disaggregation ROI exceed operational complexity cost?
A monolithic vLLM pod on a GPU server is simple to understand, simple to debug, and simple to operate. You know exactly what is running, where the bottleneck is, and what to do when it breaks. Disaggregated inference introduces a routing layer, a distributed KV-cache transfer mechanism, two independently scaling pod types, and a scheduler that learns from traffic — none of which your existing ML engineering team necessarily has operational experience with. The complexity tax is real.
The break-even point is somewhere around the level where you are hitting consistent P95 TTFT degradation under load, your GPU utilization is either pegged on prefill or starved on decode, or your inference cost per token is high enough that hardware efficiency improvements pay for the ops overhead. If you are running a handful of API endpoints serving hundreds of internal users, disaggregation is probably premature optimization. If you are running multi-agent workflows at consumer scale, or serving high-concurrency enterprise applications where latency SLO violations are measurable revenue events, you are almost certainly at the point where it matters.
The SuperML Take
The narrative around llm-d is often framed as “faster inference” — better benchmarks, lower latency, higher throughput. That framing undersells what is actually happening. This is not an optimization. It is a reclassification. LLM inference, at scale, is now a distributed systems problem with all the engineering surface that implies: service mesh routing, distributed state management, failure mode propagation across component boundaries, and operational tooling designed for multi-component topologies rather than single-process services.
That reclassification has significant consequences for enterprise AI teams who still think of inference as “run the model on a GPU.” If your inference architecture doesn’t have a routing layer, you have no visibility into per-request latency attribution. If your prefill and decode phases share hardware, you have no ability to scale them independently, and every traffic spike that hits prefill will degrade decode for every other in-flight request. These are not edge cases. They are structural properties of the monolithic architecture.
The CNCF sandbox status matters more than the v0.7 features individually. It means that predicted-latency scheduling, KV-cache-aware routing, and prefill-decode disaggregation are entering the same standardization lifecycle that gave us Kubernetes-native CI/CD, service mesh, and observability tooling. Within two to three years, running a monolithic inference stack in a production enterprise environment will feel like running a database without a connection pool — technically possible, but clearly behind where the infrastructure has moved.
The 6-to-12 month gap between where llm-d is now and where it needs to be for broad enterprise adoption is primarily operational. The framework itself is production-capable; what is not yet production-mature is the enterprise toolkit around it — runbooks, failure playbooks, cost modeling templates, integration patterns with existing LLM gateways, and certified training for operations teams. Red Hat’s inclusion in AI 3.4 is the first step in that direction. Expect Datadog, Grafana, and the major observability platforms to ship first-class llm-d dashboards by the end of 2026.
What architects and platform engineers should understand right now is that this is the moment to build the capability, not wait for it to be fully productized. The teams that understand disaggregated inference architecture today will have a two-year head start on the teams that adopt it when it is default-on in their cloud provider’s managed AI serving product.
Architecture Impact
What changes in system design? Disaggregated inference restructures LLM serving from a single-process deployment into a multi-tier distributed system with a routing layer, independently scaled prefill and decode pools, and a KV-cache transfer bus connecting them. This changes capacity planning fundamentally: instead of provisioning identical GPU instances and scaling horizontally, teams must model prefill-to-decode ratios for their specific workload and provision hardware with appropriate compute vs. memory-bandwidth profiles for each tier.
What new failure mode appears? The most operationally dangerous failure mode is silent decode starvation under prefill load spikes. When prefill pods are saturated, in-flight requests either wait in the prefill queue or overflow to already-loaded decode pods, degrading TTFT for all concurrent requests without any single request appearing to fail. This failure is invisible to a traditional infrastructure monitor watching CPU and GPU utilization; it requires per-request latency telemetry broken down by phase to detect. A secondary failure mode is KV-cache transfer latency becoming the bottleneck when network bandwidth between prefill and decode pods is insufficient for the KV-cache sizes generated by long-context requests.
What enterprise teams should evaluate:
- Platform engineering: Whether your current GPU fleet has appropriate compute-dense instances for a prefill pool and memory-bandwidth-dense instances for a decode pool — these are often different SKUs, which means disaggregation may require a procurement and capacity planning refresh before deployment.
- MLOps and observability: Whether your current inference monitoring stack can emit and correlate per-phase latency metrics (TTFT, TPOT, KV-cache hit rate, routing decisions) — Prometheus alone is insufficient; you need purpose-built LLM observability that understands the disaggregated topology.
- AI architecture: How your existing LLM gateway (LiteLLM, Portkey, etc.) integrates with the llm-d inference gateway — these are not necessarily complementary without explicit configuration, and running two routing layers without coordination will create unpredictable behavior under load.
Cost / latency / governance / reliability implications: At validated B200 topologies, disaggregation delivers up to 50,000 output tokens per second at ~3,100 tokens per second per decode GPU — roughly a 2-3x throughput improvement over equivalent monolithic deployments at the same hardware cost. The operational cost is real: disaggregated inference requires dedicated scheduling expertise and a richer observability stack, adding an estimated 15-25% to inference operations cost for teams without existing distributed systems experience. On the governance side, KV-cache transfer between pods introduces a data-in-motion surface that needs to be accounted for in data residency architectures — particularly relevant for regulated industries where prompt content may include customer data subject to sovereignty requirements.
What to Watch
The next six months of llm-d will tell you a lot about whether this becomes the default enterprise inference standard or stays a sophisticated option for teams with deep distributed systems expertise. Watch for v0.8 and v0.9 milestones to see whether the batch gateway stabilizes — async, batch inference workloads (embedding generation, document processing, offline agent tasks) are a massive enterprise use case that disaggregated architectures handle very differently from real-time serving. Watch for managed service announcements from Google Cloud and Red Hat OpenShift that abstract the operational complexity behind a managed control plane. And watch for the major LLM gateway vendors — LiteLLM, Portkey, Kong, TrueFoundry — to publish explicit llm-d integration documentation, which will be the signal that the ecosystem has decided this is production infrastructure rather than a research project.
The trajectory is clear. The question for enterprise AI teams is not whether to understand disaggregated inference — it is whether to build that understanding now or in 2027 when everyone else already has.
Sources
- llm-d GitHub Repository — Releases and v0.7 Notes
- Welcome llm-d to the CNCF — CNCF Blog
- llm-d: Intelligent Inference at Scale — Yakov Beder, Medium
- Donating llm-d to the Cloud Native Computing Foundation — IBM Research
- Predicted-Latency Based Scheduling for LLMs — llm-d.ai
- Prefill-Decode Disaggregation: The Architecture Shift Redefining LLM Serving at Scale — Groundy
- Disaggregated Inference: 18 Months Later — Hao AI Lab @ UCSD
- IBM, Red Hat, and Google Donated a Kubernetes Blueprint for LLM Inference to the CNCF — The New Stack
- Inference Optimization: The Defining LLM Infrastructure Shift for 2026 — Dev Journal
Enterprise AI Architecture
Want more enterprise AI architecture breakdowns?
Subscribe to SuperML.



