 Bhanu Pratap Singh
Bhanu Pratap Singh The Hidden Bottleneck Inside Every LLM Inference Stack — and Why llm-d v0.7 Just Made Disaggregation an Enterprise Architecture Decision
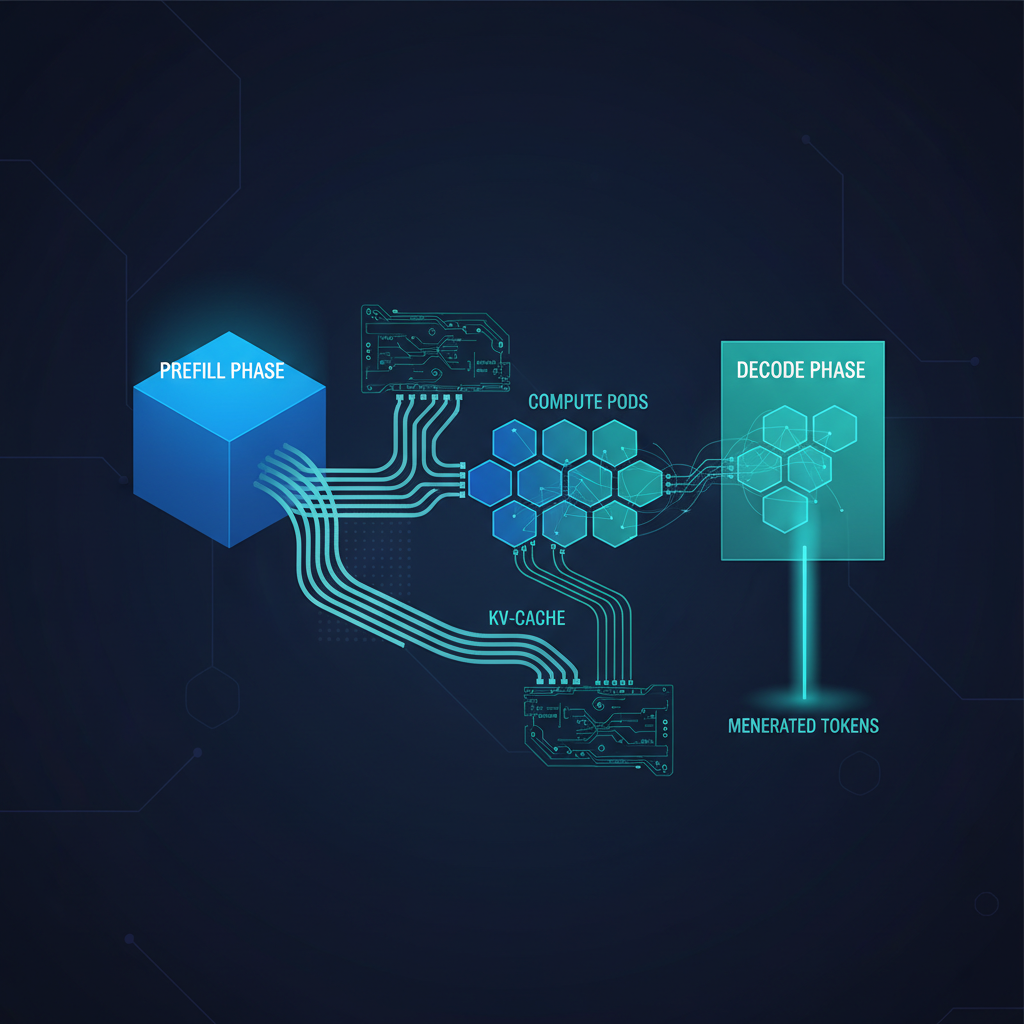
llm-d v0.7 ships predicted-latency scheduling to GA and joins the CNCF — forcing enterprise AI teams to confront the structural ceiling of monolithic inference and treat LLM serving as a real distributed systems problem.
