Anthropic's First Banking Agent Just Went Into AML. Here's the Production Architecture That Has to Hold.
FIS and Anthropic's Financial Crimes AI Agent promises to compress AML investigations from days to minutes — but the production requirements for a regulated, auditable, human-supervised agent in anti-money laundering are more demanding than any demo will show you.

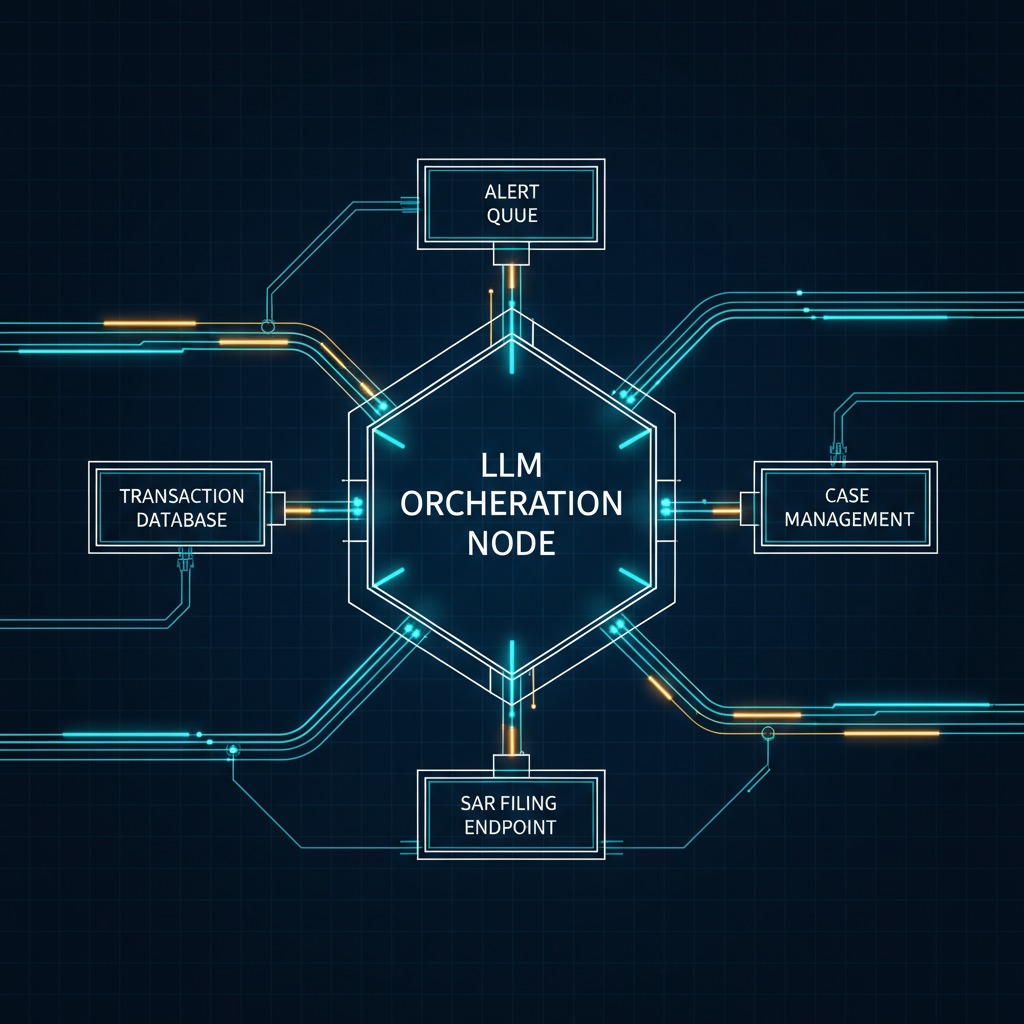
Table of Contents
On May 4th, FIS and Anthropic announced the Financial Crimes AI Agent — the first production-bound agentic AI deployment to land inside the AML compliance stack of major U.S. banks. BMO and Amalgamated Bank are named as launch partners, with broader availability across FIS’s client network planned for H2 2026. The headline promise is aggressive: AML alert and case investigations compressed from days to minutes, reduced false positives, and improved Suspicious Activity Report (SAR) narrative quality.
That is a real problem worth solving. Global AML compliance costs the financial industry an estimated $213 billion annually. Investigators spend the majority of their time on low-quality alerts — hunting for evidence across disconnected core systems, manually drafting SAR narratives that follow specific FinCEN format requirements, and making decisions on cases that arrive in waves during quarter-end review cycles. If a well-designed AI agent can handle the evidence assembly and triage workflow, a skilled investigator’s time shifts from data retrieval to genuine analysis.
But “compresses days to minutes” is a deployment claim, not an architecture specification. And in AML compliance, the gap between those two things is where regulators live.
What the Agent Actually Does (and Doesn’t Do)
The Financial Crimes AI Agent sits in the investigation layer, not the detection layer. It is not replacing the transaction monitoring system that fires alerts. It is picking up after the alert fires, doing the investigative legwork that currently consumes most of a human analyst’s time.
According to FIS, the agent automatically assembles evidence across a bank’s core systems, evaluates activity against known money laundering typologies, surfaces the highest-risk cases for investigator review, and assists in drafting SAR narratives. Human investigators retain full authority over final SAR filing decisions. Anthropic’s forward-deployed engineers are embedded with FIS to co-design the agent and, critically, build the evaluation frameworks that will govern it.
This is an evidence assembly and triage agent. That framing matters because it defines what the agent’s failure modes actually are. It is not making lending decisions, not approving transactions, not flagging customers to law enforcement. It is summarizing, prioritizing, and drafting. That is meaningfully less high-stakes than what “AI in financial crimes” typically sounds like — but it is still consequential enough that getting it wrong has serious regulatory consequences, because SARs are legal documents filed with FinCEN, and the quality and accuracy of what an agent contributes to that filing lives under the same governance umbrella as everything else in the AML program.
The Architecture Under the Hood
FIS describes the deployment as an “agent-first governed environment where client data stays within FIS-controlled infrastructure and every agent decision is traceable and auditable.” That sentence does a lot of work and deserves unpacking.
Client data within FIS-controlled infrastructure means the agent is not calling out to Anthropic’s API with raw transaction data. There is some form of data residency control — likely a dedicated deployment of Claude within FIS’s environment, or at minimum a strict data handling agreement that governs what leaves the network perimeter. For banks with data sovereignty requirements (and all major U.S. banks have them), this is not optional. It is a prerequisite for deployment.
Traceable and auditable is the harder claim. LLM reasoning is probabilistic. The same input can produce meaningfully different outputs across runs, especially at non-zero temperatures. An auditor asking “why did the agent flag this case as high priority and not that one” expects a deterministic answer — a rule, a threshold, a score with a documented methodology. What they will get from an LLM-based agent is something more like a chain of reasoning that was likely influenced by factors the agent cannot fully enumerate. That is not the same thing as an audit trail in the regulatory sense.
FIS’s “Orchestrated Intelligence” framework is presumably meant to address this. The architecture likely includes structured output schemas for case prioritization (so the agent produces a priority score plus a stated rationale), logging of tool calls and retrieved evidence, and constraints on what the agent is allowed to assert versus what it must mark as uncertain. But the implementation details of how this satisfies SR 26-2 model risk management requirements — which specifically cover generative AI and agentic AI as of April 2026 — are not public.
The $40 Billion Problem That Made This Worth Building
AML is not an arbitrary starting point. Over 50% of financial fraud now involves AI-generated components — deepfakes for identity verification bypass, synthetic identities constructed from real data fragments, AI-orchestrated mule account networks. AI-enabled fraud is projected to hit $40 billion by 2027. The alert volumes that transaction monitoring systems are generating are outpacing what human investigator headcount can review.
The practical result is triage by attrition. Banks are forced to set alert thresholds high enough to make the workload manageable, which means real suspicious activity slips through at the detection layer because the investigation layer is already saturated. An agent that genuinely handles the evidence assembly burden changes the economics of what threshold settings are defensible — if investigations are fast, you can investigate more alerts, which means you can afford to run more sensitive detection.
That is the production case for this. Not “AI makes investigators smarter” — it is “AI unlocks investigator capacity at the same time that AI-powered fraud is overwhelming detection systems.” The timing is not coincidental.
The SuperML Take
Here is what the demo version of this story looks like: an agent ingests an alert, queries three core banking systems, assembles a coherent evidence package in 90 seconds, scores the case as high-priority with a clear rationale, and produces a SAR draft that a compliance officer approves with minor edits. Impressive. Genuinely useful. The kind of thing that sells well in an enterprise POC.
Here is what the production version requires that the demo does not surface. First, core banking systems were not designed to be queried by LLM agents. FIS processes transactions for over 500 financial institutions, which means the “core systems” the agent queries are a heterogeneous collection of legacy platforms with varying API quality, data models, and latency profiles. Assembling evidence “across a bank’s core systems” in minutes requires those systems to return structured, consistent responses to agent queries — and legacy core banking infrastructure is famous for doing neither of those things reliably.
Second, SAR narrative quality is not just a writing problem. FinCEN’s SAR instructions specify exactly what fields must be populated, what language is appropriate for describing suspicious activity, and how to characterize known typologies versus inferred ones. An LLM can produce fluent, professional prose. It can also produce narratives that drift in ways that create compliance exposure — overstating certainty, characterizing activity in ways that trigger different legal implications than the bank intended, or using language that doesn’t align with the bank’s documented compliance methodology. This is a real problem in production, and it is not solved by a capable language model. It is solved by rigorous output validation against a compliance schema, version-controlled prompt templates that are themselves subject to model risk review, and regression testing every time the underlying model is updated.
Third, the false positive reduction claim needs to be read alongside false negative risk. The goal of AML isn’t to minimize false positives — it is to file accurate SARs on real suspicious activity. If the agent’s triage deprioritizes high-priority cases at a meaningful rate, that is a worse outcome than the status quo even if it dramatically reduces workload. The evaluation framework that Anthropic’s FDEs are building with FIS will define the threshold for acceptable false negative rates. That framework, and the ongoing monitoring against it, is the real product here. The agent is almost secondary.
The 6–12 month reality check: the first deployments at BMO and Amalgamated Bank will surface what production actually looks like. Expect the initial focus to be narrow — a specific alert typology, a constrained set of core system integrations, human review of every agent output before it influences a SAR. The “days to minutes” headline will apply to that constrained use case, not the broad AML investigation workflow. The path from there to something an examiner would characterize as an autonomous investigative capability is a multi-year architecture project, not a vendor announcement.
Architecture Impact
What changes in system design? The AML investigation workflow is being restructured from a linear, human-driven data retrieval process into an agent-orchestrated evidence assembly pipeline. The agent sits between the alert queue and the human investigator, consuming alerts as structured inputs, querying core banking data sources via tools, and producing prioritized case packets with draft narratives. This requires a reliable tool layer — API wrappers around core banking systems that can handle agent query patterns at investigation scale — and an output validation layer that enforces SAR compliance schemas before any output reaches an investigator.
What new failure mode appears? Evidence hallucination at the retrieval boundary. When the agent queries a core banking system and receives an incomplete or ambiguous response, an LLM’s default behavior is to fill in the gap with plausible-sounding inferences. In a SAR context, a plausible-but-incorrect connection between two transactions is a factual error in a legal document. The failure mode is not dramatic — it does not look like the agent inventing whole accounts — but it manifests as confident narrative constructions built on data retrieval errors that no individual tool call would flag as failed.
What enterprise teams should evaluate:
- AML compliance teams: How does the agent’s case prioritization score compare to experienced investigator judgment on a representative retrospective sample, specifically on true positive cases — not just alert volume reduction?
- Model risk management: Does the agent fall under SR 26-2 “consequential” classification given that its outputs influence SAR filing decisions? What validation and ongoing monitoring regime does that require?
- IT architecture teams: What is the latency profile and availability SLA for each core banking system integration the agent depends on? Agent failure in evidence assembly should route to human fallback, not produce a partial case packet.
- Legal and compliance: What is the bank’s documentation position on using AI-assisted SAR drafts? What language in the SAR itself (if any) is required to disclose AI involvement in the investigation process?
Cost / latency / governance / reliability implications: Each investigation likely involves 5–15 tool calls against core banking systems, adding integration latency on top of LLM inference time. At 90-second median investigation time and hundreds of daily alerts, the throughput demand is manageable — but burst capacity during high-alert periods (quarter end, large-scale fraud events) needs explicit capacity planning. On governance: the model itself is subject to change as Anthropic releases updates to Claude, which means every model update is a potential change in agent behavior that triggers SR 26-2 model re-validation. FIS’s “agent-first governed environment” will need a model versioning policy that pins production deployments to specific Claude versions, with explicit change management for model updates — a governance overhead that most enterprise AI teams have not yet operationalized.
What to Watch
The deployment timeline tells you a lot. H2 2026 broader availability means FIS and Anthropic have roughly two quarters of production learning from BMO and Amalgamated Bank before this becomes a standard offering. Watch for what FIS says about alert typology coverage at each stage — narrow, well-defined typologies first (layering through correspondent accounts, structuring) before complex cross-border patterns.
Watch also for how regulators respond. The OCC, Federal Reserve, and FDIC have all noted that AI in AML workflows is an area of supervisory focus. The first examination of a bank using this agent will establish the evidentiary standard for what “traceable and auditable” actually needs to mean in an examiner interview. That standard will propagate to every other bank considering similar deployments.
The FIS roadmap beyond financial crimes — credit decisioning, deposit retention, customer onboarding — is directionally interesting but structurally different from AML. AML has relatively clear regulatory constraints that actually help define what the agent should and shouldn’t do. Credit decisioning introduces fair lending law, adverse action notice requirements, and model explainability standards that are considerably harder to satisfy with a generative AI system. If the AML deployment proves the architecture, expect a multi-year gap before the credit use case is production-ready.
The MAS initiative in Singapore — where five banks are pooling transaction data to train a shared scam detection model — represents the next layer of complexity: not just deploying agents against a single bank’s data, but building shared intelligence across institutional boundaries. If AML agents prove viable within single-bank environments, cross-bank federated training architectures will be the next problem. That is a harder governance and technical challenge by an order of magnitude.
Sources
- FIS Brings Agentic AI to Banking with Anthropic, Starting with Financial Crimes — FIS Press Release
- FIS and Anthropic Pair for AI in Banking and AML — FinTech Magazine
- FIS taps Anthropic to automate AML with AI agents — Fintech Global
- Amalgamated Bank Announces Collaboration with FIS and Anthropic — Amalgamated Bank
- Financial Stability Risks Mount as Artificial Intelligence Fuels Cyberattacks — IMF
- MAS Collaborates with Banking Industry to Harness AI in the Fight Against Financial Crime — MAS Singapore
- How Criminals Use AI for Fraud in 2026 and How Banks Can Detect It — Silent Eight
Enterprise AI Architecture
Want more enterprise AI architecture breakdowns?
Subscribe to SuperML.