Part 8: LangChain Integrations and Ecosystem View Series
Part 10: Langchain Resources and Further Learning
Langchain Real-World Applications and Case Studies
Part 9 of LangChain Mastery
5/27/2025, Time spent: 0m 0s
LangChain is not just a framework—it’s the core behind a wave of powerful LLM applications. In this section, we explore real-world use cases and deployment scenarios that demonstrate how LangChain enables production-grade systems.
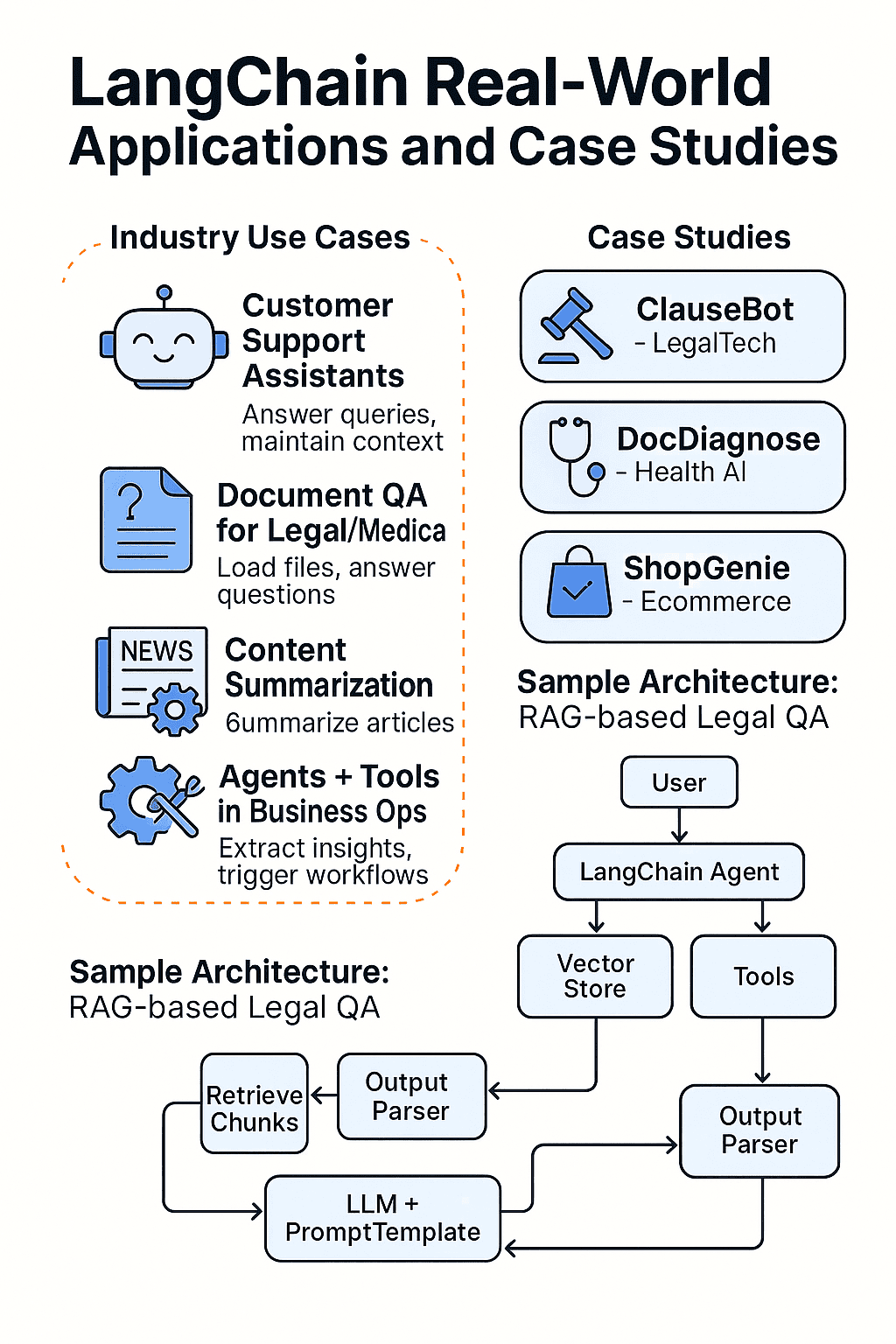
🚀 Industry Use Cases
🤖 Customer Support Assistants
AI agents built with LangChain, memory, and retrieval mechanisms can:
- Answer customer queries 24/7
- Use a vector store to reference product manuals
- Maintain context across sessions
📄 Document QA for Legal/Medical
- Load thousands of pages using
DirectoryLoaderorPyPDFLoader - Store embeddings in FAISS or Chroma
- Let users ask: “What’s the clause about liability in this contract?”
📰 Content Summarization
- Automate summarization of articles, earnings calls, legal briefs
- Combine chains like
MapReduceDocumentsChainfor better results
🛠️ Agents + Tools in Business Ops
LangChain Agents paired with tools like search APIs, CRMs, or analytics dashboards can:
- Extract insights
- Summarize daily reports
- Trigger downstream workflows (e.g., send Slack alerts)
📊 Case Studies
1. LegalTech Startup: “ClauseBot”
- Problem: Legal teams were overwhelmed with document reviews
- Solution: Built an RAG (Retrieval-Augmented Generation) app using LangChain + FAISS + OpenAI
- Result: Reduced review time by 60%
2. Health AI: “DocDiagnose”
- Built with HuggingFace LLMs + LangChain memory + prompt engineering
- Used to summarize and analyze patient notes
- Embedded documents using
SentenceTransformerand queried viaRetrievalQAChain
3. Ecommerce Assistant: “ShopGenie”
- Used LangChain agents + real-time APIs (inventory, pricing, delivery)
- Handled queries like:
- “What are my top 3 bestsellers today?”
- “Send me a summary of yesterday’s sales”
- Integrated memory to keep user session intact
🧠 Best Practices from Deployments
- Chunk intelligently: Over-chunking can lose context; under-chunking increases token cost.
- Use
metadatain docs: Store source page, title, etc. for better context during answers. - Use retry logic: LLMs may fail with long outputs—wrap chains with error handling.
- Prompt testing is critical: A/B test system and human message templates.
- Observe & log outputs: Add observability (LangSmith, tracing) to improve performance.
💡 Sample Architecture: RAG-based Legal QA
[User Query]
↓
[LangChain Agent]
↙ ↘
[VectorStore] [Tools]
↓ ↘
[Retrieved Chunks] [API Result]
↘ ↙
[LLM + PromptTemplate]
↓
[Output Parser]
↓
[Final Answer to User]🧪 Try This
- ConversationalRetrievalChain with memory
- Chroma as vector DB
- LangChain agent to call tools like a calculator or external APIs
Sample Prompt:
"What’s the key risk clause in this document? Also, calculate the interest from 2020 to 2025 at 5%."Need help bootstrapping your LangChain product idea? The next section dives into deployment strategies and productionization techniques.