FDE Architecture Framework: Build Production ML Systems That Don't Break
Feature-Decision-Execution (FDE) is the layered architecture pattern that separates ML prediction from business logic from system action — the pattern that makes production ML systems maintainable, auditable, and safe to iterate on.

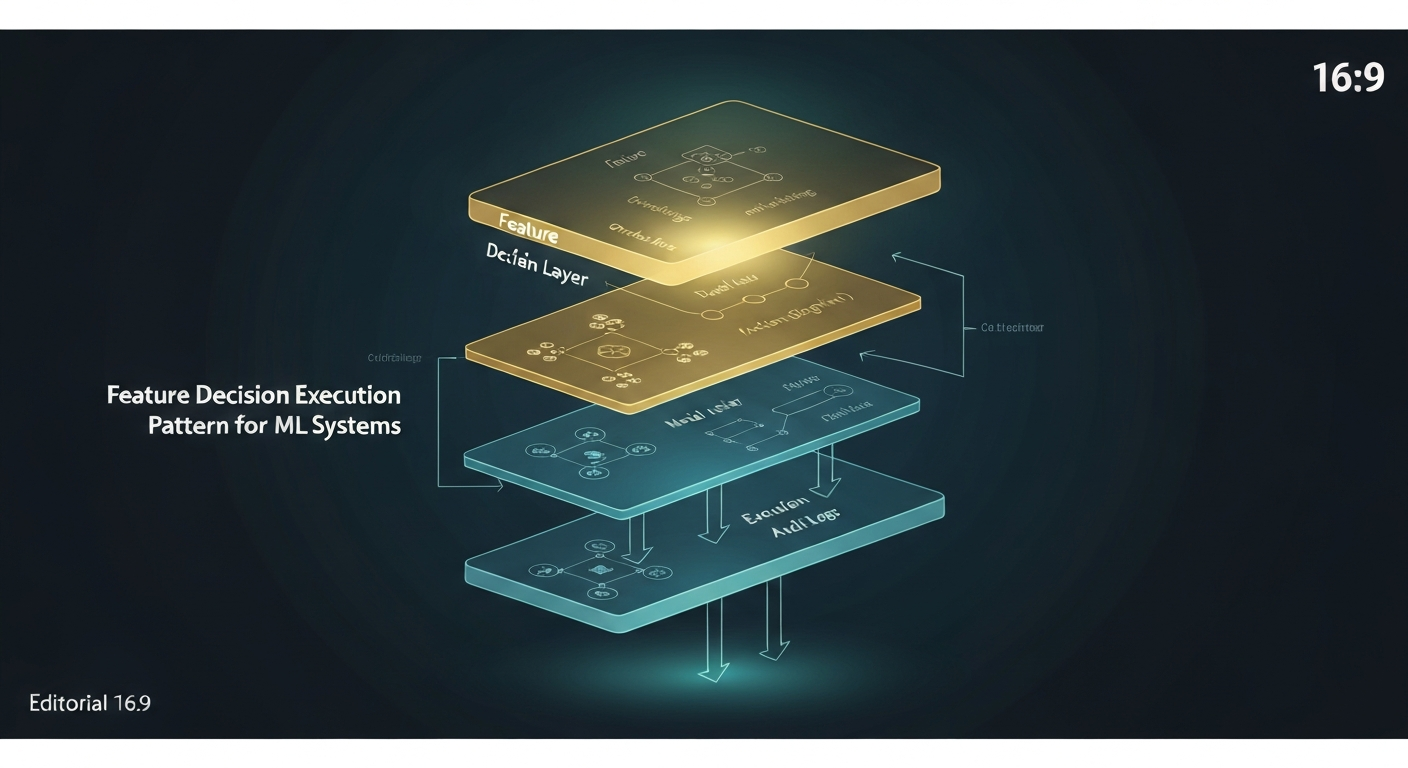
Table of Contents
FDE Architecture Framework: Build Production ML Systems That Don’t Break
Level: Intermediate
Time to complete: 60–90 minutes
Prerequisites: Python, basic familiarity with REST APIs and databases; no prior MLOps experience required
Learning Objectives
By the end of this tutorial you will be able to:
- Explain the three layers of the FDE architecture and why they are separated
- Implement each layer with a clean interface contract in Python
- Wire the layers together into a working fraud detection system
- Test each layer independently and in combination
- Deploy layers independently with different scaling and release strategies
Table of Contents
- Why Monolithic ML Services Fail
- The FDE Pattern: Three Layers, Three Concerns
- The Feature Layer: Serving ML Inputs
- The Decision Layer: Model + Business Logic
- The Execution Layer: Taking Action Safely
- Tutorial: FDE for Banking Fraud Detection
- Layer Contracts: The API Between Layers
- Testing Strategy for FDE Systems
- Deployment Patterns: Independent Layer Operations
- When to Apply FDE (and When Not To)
- Exercises
Part 1 — Why Monolithic ML Services Fail
The typical lifecycle of a monolithic ML service looks like this:
Month 1: Data scientist trains a fraud model. Engineer wraps it in a Flask app. The app reads features from the database, runs the model, writes a decision to the decisions table, calls the fraud case management API. It works.
Month 6: The model needs to be retrained. The engineer updates the model artifact, redeploys the service, and the business rules that were hardcoded alongside the model in the same function break because the output schema changed. Hotfix deployed. Three other integration points also break.
Month 12: The fraud case management API is being replaced. The new API requires a different payload structure. The engineer modifies the service. But the service also calls a legacy audit system with the old format, and that system can’t be changed without a 6-week change request. The team works around it by transforming the payload twice in the same function.
Month 18: Nobody understands the service anymore. Changing the model requires understanding the business rules. Changing the business rules requires understanding the API integrations. Changing the API integrations requires understanding the model output format. There is no test for any of it.
This is not a hypothetical. It is the standard lifecycle of 80% of production ML systems built without an explicit architecture pattern.
The root cause is the same in every case: prediction, business logic, and system action are tangled in a single service. When one changes, the others break. When something goes wrong in production, it’s unclear which layer is the source.
FDE separates these concerns at the architecture level.
Part 2 — The FDE Pattern: Three Layers, Three Concerns
┌─────────────────────────────────────────────────────────┐
│ INCOMING REQUEST │
│ (transaction, API call, event) │
└────────────────────────┬────────────────────────────────┘
│
┌──────────▼──────────┐
│ FEATURE LAYER │ ← "What do we know?"
│ │
│ • Feature serving │
│ • Signal retrieval │
│ • Feature groups │
│ • Freshness checks │
└──────────┬──────────┘
│ FeatureSet
┌──────────▼──────────┐
│ DECISION LAYER │ ← "What should we do?"
│ │
│ • ML model(s) │
│ • Business rules │
│ • Output contract │
│ • Explainability │
└──────────┬──────────┘
│ DecisionResult
┌──────────▼──────────┐
│ EXECUTION LAYER │ ← "Do it safely"
│ │
│ • Action dispatch │
│ • Idempotency │
│ • Rollback plan │
│ • Audit logging │
└──────────┬──────────┘
│ ExecutionResult
┌────▼────┐
│ CALLER │
└─────────┘Each layer has a single responsibility and communicates with adjacent layers through a typed contract. The contract is the key: it means each layer can be developed, tested, deployed, and scaled independently.
Feature Layer: given a request context (customer ID, transaction data, session info), produce the feature vector the decision layer needs. Nothing else.
Decision Layer: given a feature set, produce a decision (approve/decline/review, score, recommended action, reason codes). Nothing else.
Execution Layer: given a decision, take the appropriate action in downstream systems safely and idempotently. Nothing else.
Part 3 — The Feature Layer: Serving ML Inputs
3.1 Responsibilities
The Feature Layer is responsible for:
- Serving pre-computed features from a fast store (Redis, DynamoDB, Feast)
- Computing real-time features from the incoming request
- Joining online features with request-time signals
- Validating feature completeness and freshness
- Returning a typed
FeatureSetobject
3.2 The FeatureSet Contract
from dataclasses import dataclass, field
from typing import Optional, Dict, Any
from datetime import datetime
from enum import Enum
class FeatureFreshness(Enum):
FRESH = "fresh" # within expected refresh window
STALE = "stale" # older than expected, but available
MISSING = "missing" # not available at all
SYNTHETIC = "synthetic" # imputed from fallback logic
@dataclass
class FeatureGroup:
"""A logical group of related features with metadata."""
name: str
features: Dict[str, Any]
freshness: FeatureFreshness
computed_at: datetime
source: str # "online_store", "real_time", "fallback"
@dataclass
class FeatureSet:
"""
The contract from Feature Layer → Decision Layer.
Contains all features the decision model needs, with provenance.
"""
request_id: str
customer_id: str
timestamp: datetime
groups: Dict[str, FeatureGroup]
is_complete: bool # False if any critical group is MISSING
warnings: list = field(default_factory=list)
def get(self, group: str, feature: str, default=None):
"""Safe feature access with default fallback."""
grp = self.groups.get(group)
if grp is None or grp.freshness == FeatureFreshness.MISSING:
return default
return grp.features.get(feature, default)
def get_vector(self, group: str) -> Dict[str, Any]:
"""Get all features in a group as a flat dict."""
grp = self.groups.get(group)
if grp is None:
return {}
return grp.features3.3 Implementing the Feature Layer
import redis
import json
import numpy as np
from datetime import datetime, timedelta
from typing import Optional
import logging
logger = logging.getLogger(__name__)
class FeatureLayer:
"""
Feature serving layer for the FDE architecture.
Combines online-stored pre-computed features with real-time signals.
"""
def __init__(self, redis_url: str = "redis://localhost:6379",
freshness_threshold_minutes: int = 60):
self.redis = redis.from_url(redis_url, decode_responses=True)
self.freshness_threshold = timedelta(minutes=freshness_threshold_minutes)
def get_features(self, request_id: str, customer_id: str,
transaction: dict) -> FeatureSet:
"""
Main entry point: build a complete FeatureSet for a decisioning request.
"""
timestamp = datetime.utcnow()
groups = {}
warnings = []
# 1. Online-stored customer risk features (Redis)
groups["customer_risk"] = self._get_customer_risk(customer_id, timestamp)
# 2. Spend behaviour features (Redis, refreshed hourly)
groups["spend_behaviour"] = self._get_spend_behaviour(customer_id, timestamp)
# 3. Real-time transaction features (computed from the request itself)
groups["transaction_context"] = self._compute_transaction_features(
transaction, timestamp
)
# 4. Session risk features (real-time from request)
groups["session_context"] = self._compute_session_features(
transaction, timestamp
)
# Check completeness: "customer_risk" is always required
is_complete = groups["customer_risk"].freshness != FeatureFreshness.MISSING
if not is_complete:
warnings.append("customer_risk features missing — decisioning may degrade")
for name, group in groups.items():
if group.freshness == FeatureFreshness.STALE:
warnings.append(f"{name} features are stale (>60min old)")
return FeatureSet(
request_id=request_id,
customer_id=customer_id,
timestamp=timestamp,
groups=groups,
is_complete=is_complete,
warnings=warnings,
)
def _get_customer_risk(self, customer_id: str,
now: datetime) -> FeatureGroup:
"""Retrieve pre-computed customer risk features from Redis."""
key = f"features:customer_risk:{customer_id}"
data = self.redis.hgetall(key)
if not data:
return FeatureGroup(
name="customer_risk",
features={},
freshness=FeatureFreshness.MISSING,
computed_at=now,
source="online_store",
)
computed_at = datetime.fromisoformat(data.get("_computed_at", now.isoformat()))
age = now - computed_at
freshness = (FeatureFreshness.FRESH if age < self.freshness_threshold
else FeatureFreshness.STALE)
features = {
"credit_score": float(data.get("credit_score", 0)),
"fraud_score_30d": float(data.get("fraud_score_30d", 0)),
"account_age_months": int(data.get("account_age_months", 0)),
"dispute_count_90d": int(data.get("dispute_count_90d", 0)),
"velocity_1h": float(data.get("velocity_1h", 0)), # $ in last hour
"velocity_24h": float(data.get("velocity_24h", 0)), # $ in last 24h
"international_ratio": float(data.get("international_ratio", 0)),
}
return FeatureGroup(
name="customer_risk",
features=features,
freshness=freshness,
computed_at=computed_at,
source="online_store",
)
def _get_spend_behaviour(self, customer_id: str,
now: datetime) -> FeatureGroup:
"""Retrieve spend pattern features."""
key = f"features:spend:{customer_id}"
data = self.redis.hgetall(key)
if not data:
# Return synthetic defaults rather than MISSING for non-critical features
return FeatureGroup(
name="spend_behaviour",
features={"avg_txn_amount_30d": 0.0, "top_mcc": "unknown"},
freshness=FeatureFreshness.SYNTHETIC,
computed_at=now,
source="fallback",
)
return FeatureGroup(
name="spend_behaviour",
features={
"avg_txn_amount_30d": float(data.get("avg_txn_amount_30d", 0)),
"std_txn_amount_30d": float(data.get("std_txn_amount_30d", 0)),
"top_mcc": data.get("top_mcc", "unknown"),
"unique_merchants_7d": int(data.get("unique_merchants_7d", 0)),
"weekend_spend_ratio": float(data.get("weekend_spend_ratio", 0.5)),
},
freshness=FeatureFreshness.FRESH,
computed_at=now,
source="online_store",
)
def _compute_transaction_features(self, txn: dict,
now: datetime) -> FeatureGroup:
"""Compute features from the current transaction — always real-time."""
amount = float(txn.get("amount", 0))
is_intl = txn.get("country", "US") != "US"
is_online = txn.get("channel", "") in ("web", "mobile", "api")
is_night = now.hour < 6 or now.hour >= 22
return FeatureGroup(
name="transaction_context",
features={
"amount": amount,
"amount_log": float(np.log1p(amount)),
"is_international": int(is_intl),
"is_online": int(is_online),
"is_night": int(is_night),
"mcc": txn.get("mcc", "0000"),
"merchant_country": txn.get("country", "US"),
},
freshness=FeatureFreshness.FRESH,
computed_at=now,
source="real_time",
)
def _compute_session_features(self, txn: dict,
now: datetime) -> FeatureGroup:
"""Compute session-level risk signals."""
return FeatureGroup(
name="session_context",
features={
"device_fingerprint_match": int(txn.get("device_known", True)),
"ip_country_match": int(txn.get("ip_matches_billing", True)),
"auth_method": txn.get("auth_method", "pin"),
},
freshness=FeatureFreshness.FRESH,
computed_at=now,
source="real_time",
)Part 4 — The Decision Layer: Model + Business Logic
4.1 The DecisionResult Contract
from dataclasses import dataclass, field
from typing import List, Optional
from enum import Enum
class DecisionAction(Enum):
APPROVE = "approve"
DECLINE = "decline"
REVIEW = "review" # send to human review queue
CHALLENGE = "challenge" # step-up authentication
@dataclass
class DecisionResult:
"""
The contract from Decision Layer → Execution Layer.
Encodes what to do, why, and how confident we are.
"""
request_id: str
customer_id: str
action: DecisionAction
fraud_score: float # 0.0 (safe) to 1.0 (fraud)
confidence: float # model confidence in this decision
reason_codes: List[str] # human-readable reasons (for regulatory)
policy_applied: str # which rule or model made this decision
model_version: str
is_model_driven: bool # False if overridden by a hard rule
metadata: dict = field(default_factory=dict)4.2 Implementing the Decision Layer
import numpy as np
from sklearn.ensemble import GradientBoostingClassifier
import joblib
class DecisionLayer:
"""
Decision layer: combines ML model scores with business rules
to produce a typed DecisionResult.
Critically: business rules are explicit and auditable,
not embedded in the model.
"""
# Fraud score thresholds (easily tunable without model retrain)
DECLINE_THRESHOLD = 0.85
REVIEW_THRESHOLD = 0.60
CHALLENGE_THRESHOLD = 0.40
def __init__(self, model_path: str, model_version: str):
self.model = joblib.load(model_path)
self.model_version = model_version
def decide(self, feature_set: FeatureSet) -> DecisionResult:
"""
Core decision logic: run model, apply business rules, return result.
"""
# Step 1: Check if any hard-rule pre-empts the model
hard_rule_result = self._check_hard_rules(feature_set)
if hard_rule_result is not None:
return hard_rule_result
# Step 2: If feature set is incomplete, apply conservative policy
if not feature_set.is_complete:
return self._incomplete_features_policy(feature_set)
# Step 3: Run the ML model
fraud_score, confidence = self._score(feature_set)
# Step 4: Apply threshold policy
action, reason_codes = self._apply_thresholds(
fraud_score, confidence, feature_set
)
return DecisionResult(
request_id=feature_set.request_id,
customer_id=feature_set.customer_id,
action=action,
fraud_score=fraud_score,
confidence=confidence,
reason_codes=reason_codes,
policy_applied="gbm_v3_threshold_policy",
model_version=self.model_version,
is_model_driven=True,
)
def _check_hard_rules(self,
fs: FeatureSet) -> Optional[DecisionResult]:
"""
Hard rules that override the model.
These encode: regulatory requirements, credit policy,
known fraud patterns, and operational constraints.
"""
customer_id = fs.customer_id
# Rule 1: Immediate decline for known fraud lists (OFAC, internal blocklist)
if self._is_on_blocklist(customer_id):
return DecisionResult(
request_id=fs.request_id,
customer_id=customer_id,
action=DecisionAction.DECLINE,
fraud_score=1.0,
confidence=1.0,
reason_codes=["BLOCKED_ENTITY"],
policy_applied="hard_rule:blocklist",
model_version=self.model_version,
is_model_driven=False,
)
# Rule 2: Extreme velocity — always decline
velocity_1h = fs.get("customer_risk", "velocity_1h", 0)
if velocity_1h > 10_000:
return DecisionResult(
request_id=fs.request_id,
customer_id=customer_id,
action=DecisionAction.DECLINE,
fraud_score=0.95,
confidence=1.0,
reason_codes=["VELOCITY_EXCEEDED"],
policy_applied="hard_rule:velocity_limit",
model_version=self.model_version,
is_model_driven=False,
)
# Rule 3: International transaction on account flagged as domestic-only
if (fs.get("transaction_context", "is_international")
and fs.get("customer_risk", "international_ratio", 0) < 0.01):
# Step up to challenge rather than decline
return DecisionResult(
request_id=fs.request_id,
customer_id=customer_id,
action=DecisionAction.CHALLENGE,
fraud_score=0.50,
confidence=0.70,
reason_codes=["UNUSUAL_GEO"],
policy_applied="hard_rule:geo_challenge",
model_version=self.model_version,
is_model_driven=False,
)
return None # no hard rule fired; proceed to model
def _score(self, fs: FeatureSet) -> tuple:
"""Build feature vector and run GBM model."""
risk = fs.get_vector("customer_risk")
spend = fs.get_vector("spend_behaviour")
txn = fs.get_vector("transaction_context")
session = fs.get_vector("session_context")
# Deviation of current amount from historical average
avg = spend.get("avg_txn_amount_30d", txn.get("amount", 1))
std = spend.get("std_txn_amount_30d", avg * 0.5) or 1.0
amount_zscore = (txn.get("amount", 0) - avg) / std
X = np.array([[
risk.get("fraud_score_30d", 0),
risk.get("velocity_1h", 0) / 1000,
risk.get("velocity_24h", 0) / 10000,
risk.get("dispute_count_90d", 0),
risk.get("international_ratio", 0),
txn.get("amount_log", 0),
amount_zscore,
txn.get("is_international", 0),
txn.get("is_online", 0),
txn.get("is_night", 0),
session.get("device_fingerprint_match", 1),
session.get("ip_country_match", 1),
]])
proba = self.model.predict_proba(X)[0]
fraud_prob = float(proba[1])
confidence = float(max(proba)) # confidence is how far from 0.5
return fraud_prob, confidence
def _apply_thresholds(self, fraud_score: float, confidence: float,
fs: FeatureSet) -> tuple:
"""Map fraud score to action with reason codes."""
if fraud_score >= self.DECLINE_THRESHOLD:
action = DecisionAction.DECLINE
reasons = self._get_reason_codes(fraud_score, fs)
elif fraud_score >= self.REVIEW_THRESHOLD:
action = DecisionAction.REVIEW
reasons = self._get_reason_codes(fraud_score, fs)
elif fraud_score >= self.CHALLENGE_THRESHOLD:
action = DecisionAction.CHALLENGE
reasons = ["ELEVATED_RISK"]
else:
action = DecisionAction.APPROVE
reasons = ["WITHIN_NORMAL_PARAMETERS"]
return action, reasons
def _get_reason_codes(self, score: float,
fs: FeatureSet) -> List[str]:
"""Generate regulatory-grade reason codes (FCRA compliant)."""
codes = []
if fs.get("customer_risk", "velocity_1h", 0) > 2000:
codes.append("HIGH_VELOCITY")
if fs.get("transaction_context", "is_international"):
codes.append("INTERNATIONAL_TRANSACTION")
if fs.get("transaction_context", "is_night"):
codes.append("UNUSUAL_TIME")
if not fs.get("session_context", "device_fingerprint_match", True):
codes.append("UNRECOGNISED_DEVICE")
if not codes:
codes.append("MODEL_RISK_SCORE")
return codes[:4] # max 4 reason codes per FCRA
def _incomplete_features_policy(self, fs: FeatureSet) -> DecisionResult:
"""Conservative policy when features are missing."""
return DecisionResult(
request_id=fs.request_id,
customer_id=fs.customer_id,
action=DecisionAction.REVIEW,
fraud_score=0.50,
confidence=0.10,
reason_codes=["INSUFFICIENT_FEATURES"],
policy_applied="fallback:incomplete_features",
model_version=self.model_version,
is_model_driven=False,
metadata={"warnings": fs.warnings},
)
def _is_on_blocklist(self, customer_id: str) -> bool:
# In production: call blocklist service or Redis set
return FalsePart 5 — The Execution Layer: Taking Action Safely
5.1 Responsibilities
The Execution Layer takes the DecisionResult and acts on it. Its responsibilities are:
- Routing: send the decision to the right downstream system (approve → payment rails, decline → decline handler, review → case management queue)
- Idempotency: ensure that retried requests don’t double-execute actions
- Audit logging: write an immutable record of every action taken
- Rollback: for reversible actions, maintain rollback capability
5.2 Implementing the Execution Layer
import uuid
import time
import redis
from typing import Optional
from dataclasses import dataclass
@dataclass
class ExecutionResult:
"""The response from the Execution Layer back to the caller."""
request_id: str
action_taken: str
success: bool
reference_id: Optional[str] # downstream system reference
is_idempotent: bool # True if this was a duplicate request
audit_trail_id: str
error: Optional[str] = None
class ExecutionLayer:
"""
Execution layer: safely dispatches decisions to downstream systems.
Handles idempotency, audit logging, and rollback for reversible actions.
"""
def __init__(self, redis_url: str, audit_logger, payment_client,
review_queue_client):
self.redis = redis.from_url(redis_url)
self.audit = audit_logger
self.payments = payment_client
self.review_queue = review_queue_client
self.idempotency_ttl = 86400 # 24 hours
def execute(self, decision: DecisionResult,
transaction: dict) -> ExecutionResult:
"""
Main entry point: execute the decision safely.
"""
# Step 1: Idempotency check
idempotency_key = f"exec:idempotent:{decision.request_id}"
existing = self.redis.get(idempotency_key)
if existing:
# Request already processed — return cached result
cached = json.loads(existing)
return ExecutionResult(
request_id=decision.request_id,
action_taken=cached["action_taken"],
success=True,
reference_id=cached.get("reference_id"),
is_idempotent=True,
audit_trail_id=cached["audit_trail_id"],
)
# Step 2: Execute the action
audit_id = str(uuid.uuid4())
result = self._dispatch(decision, transaction, audit_id)
# Step 3: Write to audit log (always — even on failure)
self.audit.write({
"audit_trail_id": audit_id,
"request_id": decision.request_id,
"customer_id": decision.customer_id,
"decision": decision.action.value,
"fraud_score": decision.fraud_score,
"reason_codes": decision.reason_codes,
"policy_applied": decision.policy_applied,
"model_version": decision.model_version,
"is_model_driven": decision.is_model_driven,
"action_taken": result.action_taken,
"success": result.success,
"reference_id": result.reference_id,
"timestamp": time.time(),
"transaction": transaction,
})
# Step 4: Cache for idempotency
if result.success:
self.redis.setex(
idempotency_key,
self.idempotency_ttl,
json.dumps({
"action_taken": result.action_taken,
"reference_id": result.reference_id,
"audit_trail_id": audit_id,
}),
)
return result
def _dispatch(self, decision: DecisionResult,
txn: dict, audit_id: str) -> ExecutionResult:
"""Route decision to the appropriate handler."""
action = decision.action
if action == DecisionAction.APPROVE:
return self._handle_approve(decision, txn, audit_id)
elif action == DecisionAction.DECLINE:
return self._handle_decline(decision, txn, audit_id)
elif action == DecisionAction.REVIEW:
return self._handle_review(decision, txn, audit_id)
elif action == DecisionAction.CHALLENGE:
return self._handle_challenge(decision, txn, audit_id)
else:
raise ValueError(f"Unknown action: {action}")
def _handle_approve(self, decision, txn, audit_id) -> ExecutionResult:
"""Approve: authorise the transaction on the payment rails."""
try:
ref = self.payments.authorise(
transaction_id=txn["transaction_id"],
amount=txn["amount"],
merchant=txn["merchant_id"],
auth_code=str(uuid.uuid4())[:8].upper(),
)
return ExecutionResult(
request_id=decision.request_id,
action_taken="approved",
success=True,
reference_id=ref,
is_idempotent=False,
audit_trail_id=audit_id,
)
except Exception as e:
return ExecutionResult(
request_id=decision.request_id,
action_taken="approve_failed",
success=False,
reference_id=None,
is_idempotent=False,
audit_trail_id=audit_id,
error=str(e),
)
def _handle_decline(self, decision, txn, audit_id) -> ExecutionResult:
"""Decline: reject the transaction with reason codes."""
self.payments.decline(
transaction_id=txn["transaction_id"],
decline_codes=decision.reason_codes,
)
return ExecutionResult(
request_id=decision.request_id,
action_taken="declined",
success=True,
reference_id=None,
is_idempotent=False,
audit_trail_id=audit_id,
)
def _handle_review(self, decision, txn, audit_id) -> ExecutionResult:
"""Review: route to human fraud analyst queue."""
case_id = self.review_queue.enqueue({
"transaction": txn,
"fraud_score": decision.fraud_score,
"reason_codes": decision.reason_codes,
"audit_trail_id": audit_id,
"priority": "high" if decision.fraud_score > 0.75 else "normal",
})
return ExecutionResult(
request_id=decision.request_id,
action_taken="queued_for_review",
success=True,
reference_id=case_id,
is_idempotent=False,
audit_trail_id=audit_id,
)
def _handle_challenge(self, decision, txn, audit_id) -> ExecutionResult:
"""Challenge: trigger step-up authentication flow."""
challenge_id = self.payments.initiate_challenge(
transaction_id=txn["transaction_id"],
challenge_type="otp_sms",
)
return ExecutionResult(
request_id=decision.request_id,
action_taken="challenge_initiated",
success=True,
reference_id=challenge_id,
is_idempotent=False,
audit_trail_id=audit_id,
)Part 6 — Tutorial: Wire It Together
6.1 The FDE Orchestrator
import uuid
import logging
logger = logging.getLogger(__name__)
class FraudDecisionService:
"""
FDE orchestrator for the fraud decision system.
Coordinates Feature → Decision → Execution, handles errors at each layer.
"""
def __init__(self, feature_layer: FeatureLayer,
decision_layer: DecisionLayer,
execution_layer: ExecutionLayer):
self.features = feature_layer
self.decision = decision_layer
self.execution = execution_layer
def process(self, transaction: dict) -> dict:
"""
Full FDE pipeline for a single transaction.
Returns a structured response for the calling payment system.
"""
request_id = transaction.get("request_id") or str(uuid.uuid4())
customer_id = transaction["customer_id"]
# ── Layer 1: Features ─────────────────────────────────────────────────
try:
feature_set = self.features.get_features(
request_id=request_id,
customer_id=customer_id,
transaction=transaction,
)
except Exception as e:
logger.error(f"Feature layer failed for {request_id}: {e}")
# Fail open with synthetic empty features (or fail closed — your policy)
feature_set = FeatureSet(
request_id=request_id,
customer_id=customer_id,
timestamp=datetime.utcnow(),
groups={},
is_complete=False,
warnings=[f"Feature layer error: {e}"],
)
# ── Layer 2: Decision ─────────────────────────────────────────────────
try:
decision = self.decision.decide(feature_set)
except Exception as e:
logger.error(f"Decision layer failed for {request_id}: {e}")
# Safe fallback: review rather than approve or decline
decision = DecisionResult(
request_id=request_id,
customer_id=customer_id,
action=DecisionAction.REVIEW,
fraud_score=0.5,
confidence=0.0,
reason_codes=["DECISION_SYSTEM_ERROR"],
policy_applied="fallback:system_error",
model_version="unknown",
is_model_driven=False,
)
# ── Layer 3: Execution ────────────────────────────────────────────────
try:
result = self.execution.execute(decision, transaction)
except Exception as e:
logger.critical(f"Execution layer failed for {request_id}: {e}")
return {
"request_id": request_id,
"status": "error",
"action": "system_error",
"error": str(e),
}
return {
"request_id": request_id,
"action": result.action_taken,
"reference_id": result.reference_id,
"fraud_score": decision.fraud_score,
"reason_codes": decision.reason_codes,
"audit_trail_id": result.audit_trail_id,
"model_version": decision.model_version,
}6.2 Usage Example
# Initialise the service (in production: inject via DI container)
service = FraudDecisionService(
feature_layer=FeatureLayer(redis_url="redis://localhost:6379"),
decision_layer=DecisionLayer(
model_path="models/fraud_gbm_v3.joblib",
model_version="v3.2.1",
),
execution_layer=ExecutionLayer(
redis_url="redis://localhost:6379",
audit_logger=AuditLogger(),
payment_client=PaymentClient(),
review_queue_client=ReviewQueueClient(),
),
)
# Process a transaction
result = service.process({
"request_id": "txn-20260612-001",
"customer_id": "customer_8472",
"transaction_id": "auth-0001-20260612",
"amount": 1850.00,
"merchant_id": "merchant_12345",
"mcc": "5411", # grocery store
"country": "US",
"channel": "mobile",
"device_known": True,
"ip_matches_billing": True,
"auth_method": "biometric",
})
print(result)
# {'request_id': 'txn-20260612-001', 'action': 'approved',
# 'reference_id': 'AUTH-7F3A', 'fraud_score': 0.12,
# 'reason_codes': ['WITHIN_NORMAL_PARAMETERS'],
# 'audit_trail_id': '...', 'model_version': 'v3.2.1'}Part 7 — Layer Contracts: The API Between Layers
The contracts (FeatureSet, DecisionResult, ExecutionResult) are the most important part of the FDE architecture. Here’s what makes a good contract:
Typed and validated. Use Python dataclasses, Pydantic, or a schema registry. Untyped dicts between layers are the first step toward the monolith failure mode.
Versioned. When the Decision Layer adds a new field to DecisionResult, the Execution Layer should not break. Design contracts with forward-compatibility in mind: add fields, don’t remove them; use Optional types for new fields.
Observable. Every contract exchange should be logged at the INFO level with at minimum: request_id, timestamp, layer, and key decision fields. This is what makes the system debuggable when something goes wrong.
Documented. Every field should have a docstring. Future engineers reading the code shouldn’t need to trace through three layers to understand what confidence means in DecisionResult.
Part 8 — Testing Strategy for FDE Systems
One of the most powerful properties of FDE is testability. Each layer can be tested independently.
import pytest
from unittest.mock import MagicMock, patch
class TestDecisionLayer:
"""Unit tests for the Decision Layer — no Feature or Execution Layer needed."""
def setup_method(self):
self.decision = DecisionLayer(
model_path="tests/fixtures/mock_model.joblib",
model_version="test-v1",
)
def test_hard_rule_velocity_triggers_decline(self):
"""Velocity hard rule should decline before model runs."""
fs = FeatureSet(
request_id="test-001",
customer_id="c001",
timestamp=datetime.utcnow(),
groups={
"customer_risk": FeatureGroup(
name="customer_risk",
features={"velocity_1h": 15000.0}, # exceeds $10K limit
freshness=FeatureFreshness.FRESH,
computed_at=datetime.utcnow(),
source="online_store",
),
"transaction_context": FeatureGroup(
name="transaction_context",
features={"is_international": 0, "amount": 500.0, "amount_log": 6.2},
freshness=FeatureFreshness.FRESH,
computed_at=datetime.utcnow(),
source="real_time",
),
"session_context": FeatureGroup(
name="session_context",
features={},
freshness=FeatureFreshness.FRESH,
computed_at=datetime.utcnow(),
source="real_time",
),
"spend_behaviour": FeatureGroup(
name="spend_behaviour",
features={},
freshness=FeatureFreshness.SYNTHETIC,
computed_at=datetime.utcnow(),
source="fallback",
),
},
is_complete=True,
)
result = self.decision.decide(fs)
assert result.action == DecisionAction.DECLINE
assert result.is_model_driven == False
assert "VELOCITY_EXCEEDED" in result.reason_codes
def test_normal_transaction_approves(self):
"""Low-risk transaction should approve."""
# Build a low-risk feature set
fs = build_low_risk_feature_set("test-002", "c002")
result = self.decision.decide(fs)
assert result.action == DecisionAction.APPROVE
assert result.fraud_score < 0.40
def test_incomplete_features_route_to_review(self):
"""Incomplete feature set should trigger review, not approve."""
fs = FeatureSet(
request_id="test-003", customer_id="c003",
timestamp=datetime.utcnow(), groups={},
is_complete=False, warnings=["customer_risk missing"],
)
result = self.decision.decide(fs)
assert result.action == DecisionAction.REVIEW
assert "INSUFFICIENT_FEATURES" in result.reason_codes
class TestFDEIntegration:
"""Integration tests: all three layers working together."""
def test_full_pipeline_approve(self):
"""End-to-end: normal transaction should be approved."""
service = build_test_service() # uses test doubles for external systems
result = service.process(build_normal_transaction())
assert result["action"] == "approved"
assert result["fraud_score"] < 0.40
def test_idempotency(self):
"""Same request_id processed twice should return same result."""
service = build_test_service()
txn = build_normal_transaction()
result1 = service.process(txn)
result2 = service.process(txn) # same request_id
assert result1["action"] == result2["action"]
assert result1["audit_trail_id"] == result2["audit_trail_id"]
# Second call should be idempotentPart 9 — Deployment: Independent Layer Operations
The FDE architecture enables a deployment pattern that monolithic services can’t support: layer-level canary releases.
┌─────────────────────────────────────────────────────────────┐
│ CANARY DEPLOYMENT │
│ │
│ Feature Layer v1.2 ──→ Decision Layer v3 (90%) ──→ Exec│
│ └──→ Decision Layer v4 (10%) ──→ Exec│
│ │
│ This lets you A/B test a new model without │
│ touching the Feature or Execution layers. │
└─────────────────────────────────────────────────────────────┘Canary pattern for the Decision Layer:
import random
class CanaryDecisionLayer:
"""
Routes a percentage of traffic to a candidate Decision Layer
while keeping the rest on the stable version.
"""
def __init__(self, stable: DecisionLayer, candidate: DecisionLayer,
candidate_pct: float = 0.10):
self.stable = stable
self.candidate = candidate
self.pct = candidate_pct
def decide(self, feature_set: FeatureSet) -> DecisionResult:
if random.random() < self.pct:
result = self.candidate.decide(feature_set)
result.metadata["canary"] = True
else:
result = self.stable.decide(feature_set)
result.metadata["canary"] = False
return resultShadow mode — run the new layer in parallel but don’t use its output — is the safest way to validate a new Decision Layer before any traffic switches:
class ShadowDecisionLayer:
"""
Runs the shadow layer in parallel for comparison, but returns stable output.
Logs shadow vs stable divergence for analysis.
"""
def __init__(self, stable: DecisionLayer, shadow: DecisionLayer,
metrics_client):
self.stable = stable
self.shadow = shadow
self.metrics = metrics_client
def decide(self, feature_set: FeatureSet) -> DecisionResult:
stable_result = self.stable.decide(feature_set)
# Run shadow asynchronously (don't block on it)
try:
shadow_result = self.shadow.decide(feature_set)
agrees = stable_result.action == shadow_result.action
self.metrics.record("shadow_agreement", int(agrees), tags={
"stable_action": stable_result.action.value,
"shadow_action": shadow_result.action.value,
})
except Exception as e:
self.metrics.record("shadow_error", 1)
return stable_result # always return stablePart 10 — When to Apply FDE (and When Not To)
Apply FDE when:
- The system takes actions in downstream systems (not just returns predictions)
- Multiple teams own different parts of the pipeline (data engineering owns Feature, ML owns Decision, platform engineering owns Execution)
- Regulatory audit trails are required
- You need to be able to change the model without changing the action logic
- Latency budget allows for the overhead of layer boundaries (adds ~5–10ms for well-implemented serialisation)
Don’t apply FDE when:
- You’re building a pure prediction service that returns a score with no action
- The system is small enough that a single team maintains the entire pipeline
- Latency budget is so tight (< 10ms) that layer boundaries are prohibitive
- The model and business logic are fundamentally inseparable (e.g., the business logic is just a thin wrapper on the model output)
FDE is an architectural pattern for systems that act, not just systems that predict. If your system returns a score and a human or another system decides what to do with it, a simpler architecture is appropriate.
Part 11 — Exercises
Exercise 1: Add a Fourth Layer — Feedback
A production FDE system needs a fourth layer: Feedback, which observes the outcomes of executed decisions and routes them back to the Feature Layer (to update online features) and the Decision Layer (to trigger model retraining).
Design and implement a FeedbackLayer class that:
- Accepts feedback events (transaction disputed, fraud confirmed, challenge passed)
- Updates the customer’s
velocity_1handfraud_score_30din Redis - Logs feedback events to a stream for offline model retraining
- Closes the loop: the next transaction for this customer uses updated features
Exercise 2: Rate Limiting in the Execution Layer
The Execution Layer should rate-limit decline actions per customer: if a customer has been declined 3 times in 10 minutes, the 4th request should be escalated to a human review rather than auto-declined.
Add this logic to ExecutionLayer._handle_decline() using Redis counters with TTL. What should happen to the idempotency cache when a declined request is re-routed to review?
Exercise 3: Feature Layer Fallback Hierarchy
The Feature Layer currently falls back to a synthetic default when spend_behaviour is missing. Implement a tiered fallback hierarchy:
- First: try the online Redis store
- Second: try a warm cache (recent data from the last 24h, stored in a secondary Redis key)
- Third: compute an approximate feature from the incoming transaction itself
- Last resort: return SYNTHETIC with a global mean value
Add a fallback_tier field to FeatureGroup to track which tier served each feature.
Exercise 4: Explainability Endpoint
Add a /explain/{request_id} API endpoint to the FDE service that returns:
- The feature values that were used for this decision
- Which features were most influential (SHAP values from the GBM model)
- Whether a hard rule or the model made the decision
- The full audit trail for regulatory inquiry
Exercise 5: Multi-Model Decision Layer
Extend the Decision Layer to support a model ensemble: GBM as the primary scorer, a logistic regression as a second check, and a rule-based anomaly detector. Implement a VotingDecisionLayer that:
- Takes the maximum fraud score from all three
- Requires two-out-of-three agreement before approving a transaction above $5,000
- Logs which model(s) drove the decision
Summary
| Layer | Responsibility | Input | Output |
|---|---|---|---|
| Feature | ”What do we know?“ | request_id, customer_id, transaction | FeatureSet |
| Decision | ”What should we do?” | FeatureSet | DecisionResult |
| Execution | ”Do it safely” | DecisionResult, transaction | ExecutionResult |
The FDE pattern doesn’t make ML easier. It makes production ML maintainable — which is harder and more important. The model you build today will be replaced in 18 months. The architecture you build today will outlast three model generations. Build it right.
Further Reading
- Designing ML Systems — Chip Huyen (2022) — Chapter 7 covers serving patterns that align with FDE
- Feast Feature Store Documentation
- Real-Time ML for Production — Made With ML
- The ML Test Score — Breck et al., Google (2017)
- Rules of Machine Learning — Google
Enterprise AI Architecture
Want more enterprise AI architecture breakdowns?
Subscribe to SuperML.