🏷️ Support Vector Machines (SVM): A Powerful Tool for Classification Decoded: The Complete Guide That Will Make You an Classification Expert!
Learn how Support Vector Machines work with real-world examples, visual intuition, and Python code for classification tasks.


Table of Contents
🧠 What is a Support Vector Machine?
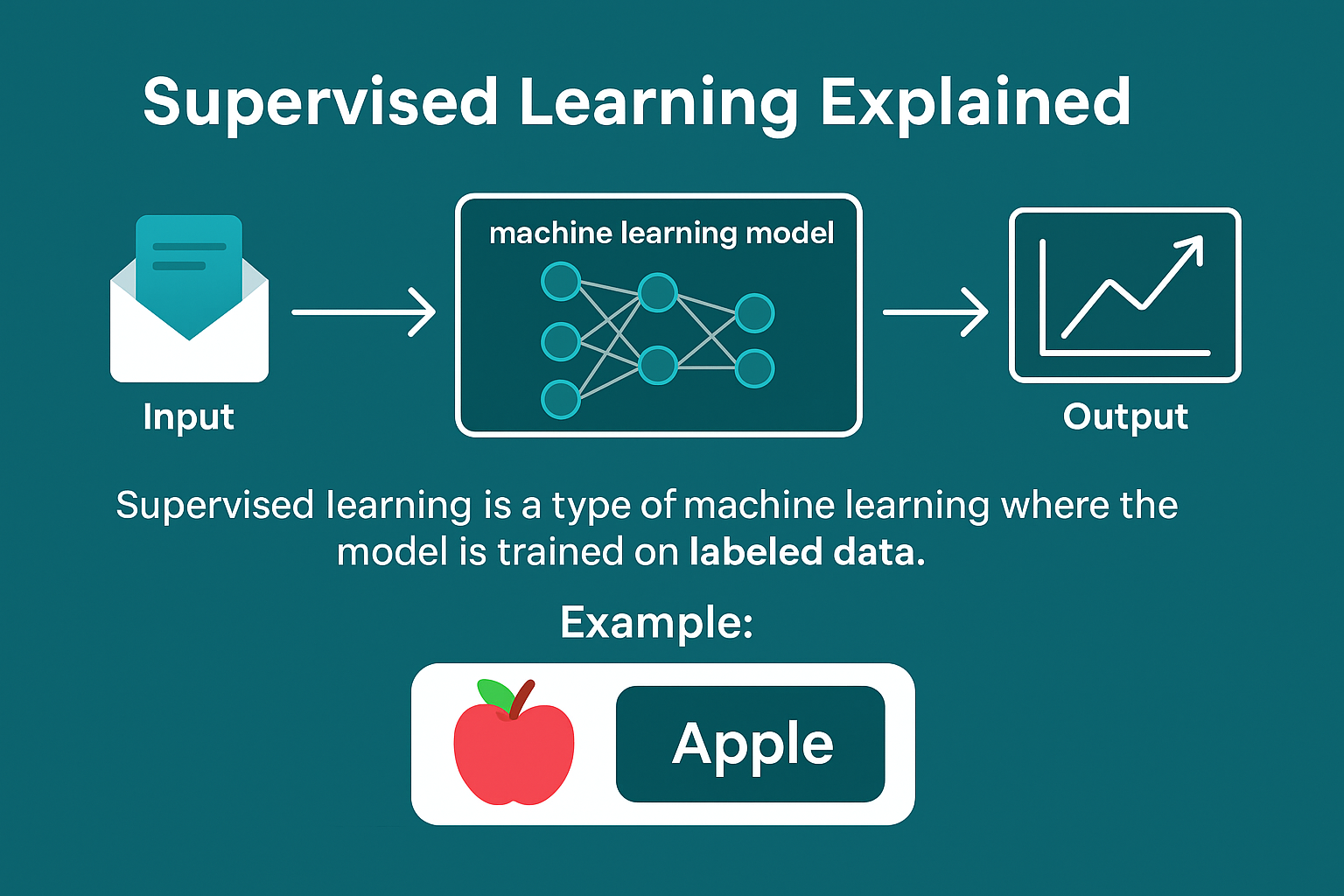
Support Vector Machines (SVM) are powerful and flexible supervised learning models used for classification and regression. They are particularly well-known for their effectiveness in high-dimensional spaces and binary classification problems.
📌 Goal: Find the hyperplane that best separates the data into different classes with the maximum margin.
📐 The Core Concept
SVM works by finding the optimal hyperplane that maximally separates the classes. A hyperplane is a decision boundary.
In 2D, it’s a line. In 3D, it’s a plane. In higher dimensions, it’s called a hyperplane.
- Support Vectors: The data points closest to the decision boundary.
- Margin: The distance between the hyperplane and the nearest data points (support vectors). SVM maximizes this margin.
🔄 Linear vs Non-Linear SVM
🔹 Linear SVM
Used when data is linearly separable.
🔸 Non-Linear SVM
When data is not linearly separable, SVM uses a kernel trick to project data into a higher-dimensional space where it becomes separable.
Common kernels:
- Linear
- Polynomial
- Radial Basis Function (RBF)
💻 Python Code Example (SVM with Scikit-Learn)
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
# Load data
iris = datasets.load_iris()
X = iris.data[:, :2] # use first two features for visualization
y = iris.target
# Binary classification (only 2 classes for simplicity)
X = X[y != 2]
y = y[y != 2]
# Split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Model
model = SVC(kernel='linear', C=1.0)
model.fit(X_train, y_train)
# Evaluate
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred))📊 Visualizing the Decision Boundary
import numpy as np
# Create a mesh grid
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k')
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.title("SVM Decision Boundary")
plt.show()✅ Pros
- Works well in high-dimensional spaces
- Effective when number of features > number of samples
- Versatile with different kernel functions
❌ Cons
- Computationally intensive for large datasets
- Requires careful tuning of hyperparameters (C, kernel type, gamma)
- Less interpretable compared to models like logistic regression
🌍 Real-World Applications
- Text classification (e.g., spam detection)
- Image recognition
- Bioinformatics (e.g., cancer detection)
- Handwritten digit classification
🧭 Conclusion
Support Vector Machines offer a powerful, margin-based approach to classification. With the ability to handle both linear and complex non-linear data through kernels, SVM remains a go-to method in many applications.
Explore its performance on your own datasets and experiment with kernel types and hyperparameters to see the magic of SVM in action!
Related Reading
- 🔥 Transformer Encoder With Python Decoded: The Complete Guide That Will Make You an Transformer Expert!
- 🔥 Transformer Encoder Decoded: The Complete Guide That Will Make You an Transformer Expert!
- Supervised Learning: A Beginner-Friendly Guide with Examples Decoded: The Complete Guide That Will Make You an Expert!
Enterprise AI Architecture
Want more enterprise AI architecture breakdowns?
Subscribe to SuperML.