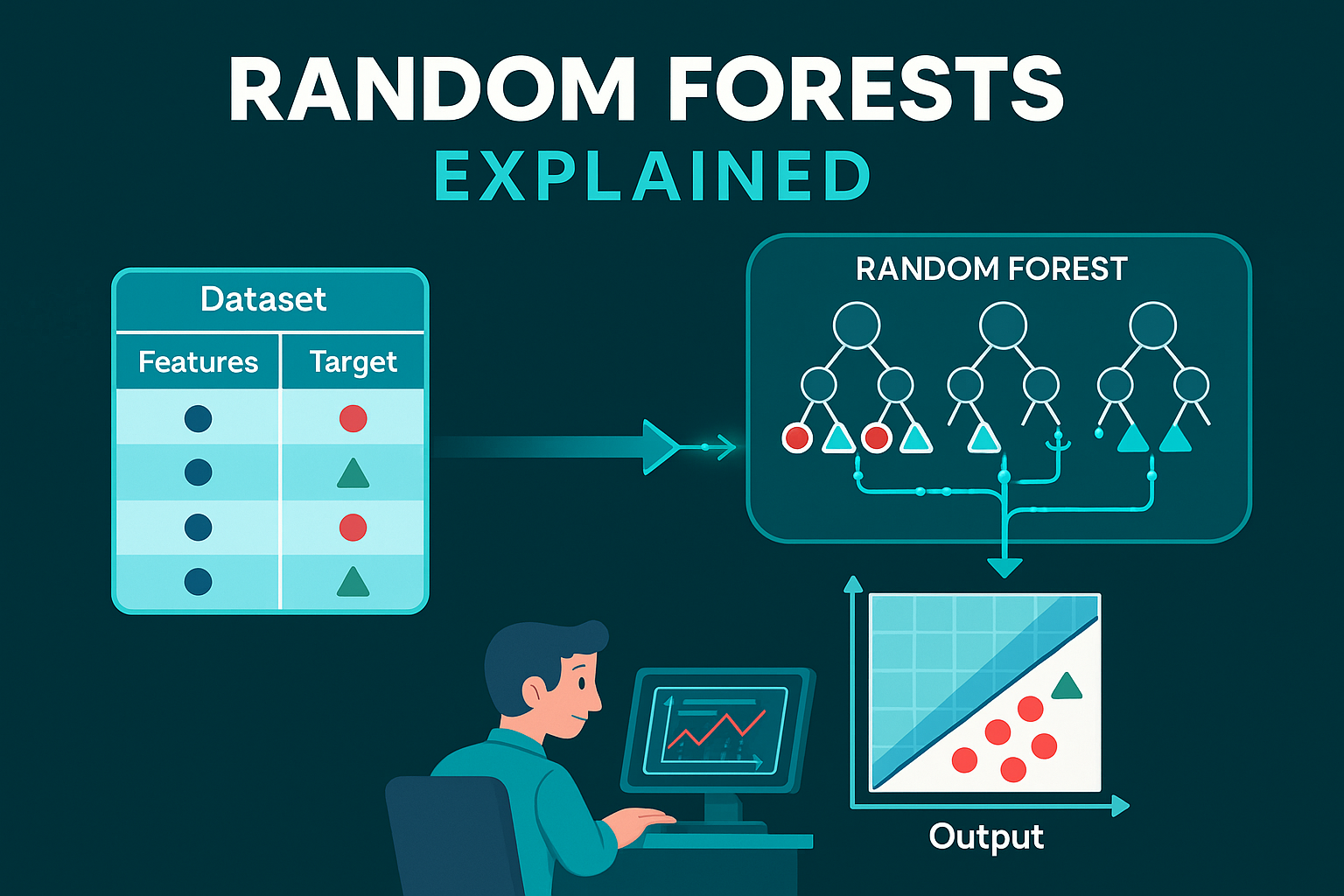
Random Forests Explained: A Powerful Ensemble Learning Method
Understand how Random Forests work with intuitive explanations, real-world applications, and a hands-on Python code example.
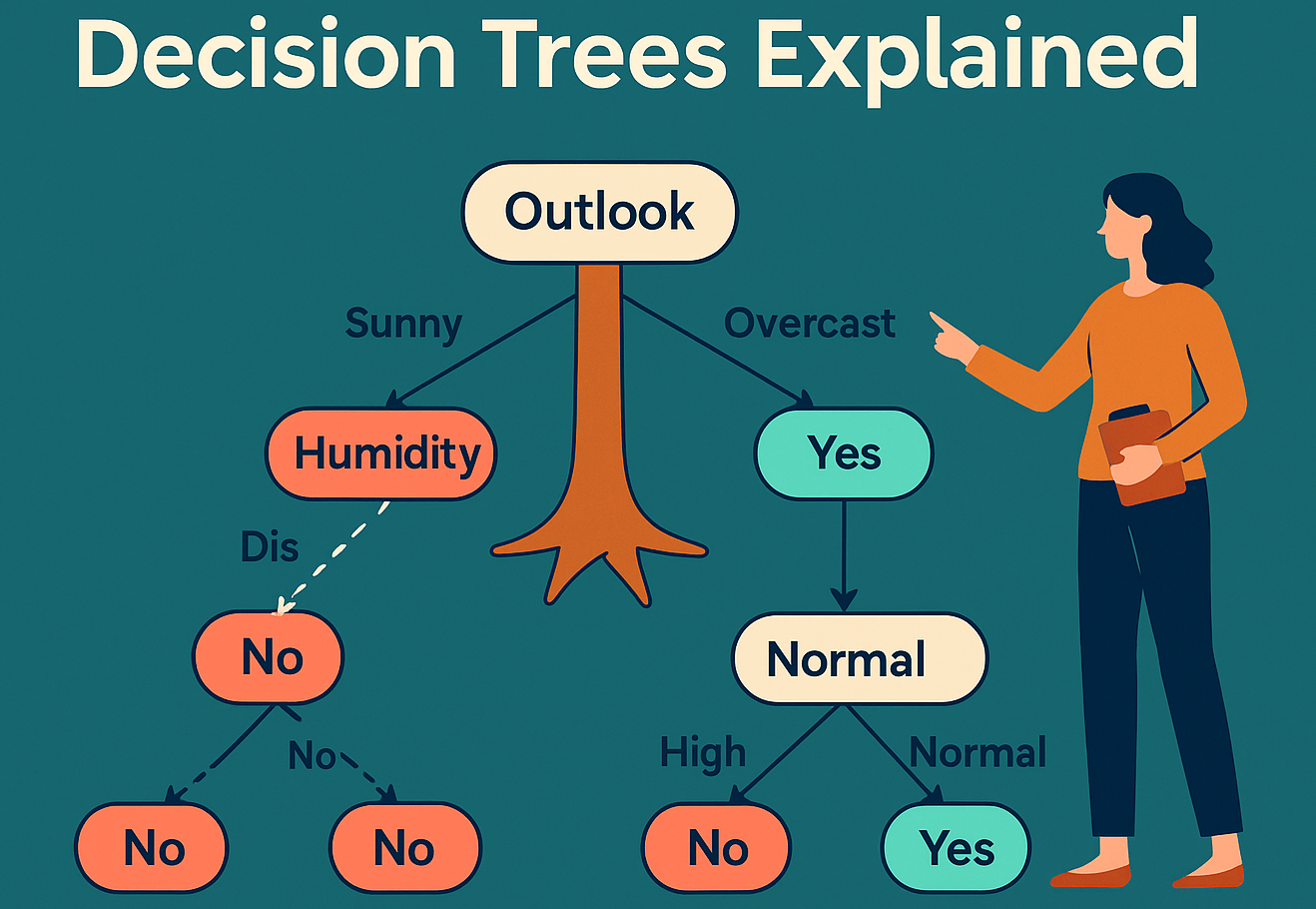
🌲 What is a Random Forest?
A Random Forest is an ensemble learning technique that builds multiple decision trees and merges their results to improve accuracy and reduce overfitting. It’s commonly used for both classification and regression problems.
📌 Think of it as a “forest” of decision trees, each trained on a random subset of the data and features.
🧠 How It Works
Bootstrap Aggregation (Bagging):
Random subsets of the data are used to train each tree.Random Feature Selection:
At each node, a random subset of features is used to split data, introducing variation among trees.Voting/Averaging:
- For classification: majority voting decides the final output.
- For regression: the average prediction is used.
🔁 Why Use Random Forest?
- Handles both categorical and numerical data
- Reduces variance (compared to single decision trees)
- Works well with missing data and large datasets
- Requires less tuning than many other models
💻 Python Example: Classifying Iris Species
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# Load data
X, y = load_iris(return_X_y=True)
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Create model
rf = RandomForestClassifier(n_estimators=100, max_depth=3, random_state=42)
rf.fit(X_train, y_train)
# Predict and evaluate
y_pred = rf.predict(X_test)
print(classification_report(y_test, y_pred))✅ Advantages
- High accuracy
- Resilient to overfitting (due to ensemble effect)
- Can handle large datasets efficiently
- Provides feature importance
- Better for imbalance classes
❌ Limitations
- Less interpretable than a single decision tree
- Slower training with many trees
- Larger model size
🌍 Real-World Applications
- Credit scoring
- Disease diagnosis
- Stock price movement prediction
- Customer churn modeling
📊 Feature Importance Visualization
import matplotlib.pyplot as plt
# Plot feature importance
plt.barh(range(X.shape[1]), rf.feature_importances_)
plt.yticks(range(X.shape[1]), ['sepal length', 'sepal width', 'petal length', 'petal width'])
plt.xlabel("Feature Importance")
plt.title("Random Forest - Feature Importance")
plt.show()🧭 Conclusion
Random Forests combine the simplicity of decision trees with the power of ensemble learning. They’re robust, accurate, and versatile—making them one of the most widely used algorithms in the machine learning toolkit.
Try it on your dataset, tweak the number of trees, and explore the feature importance it uncovers!