🔥 How to Fine-Tune a Hugging Face Transformer on Your Own Dataset That Will 10x Your Transformer Expert!
A practical, hands-on tutorial to fine-tune Hugging Face Transformers like BERT for your custom NLP dataset. Ideal for developers and ML enthusiasts.

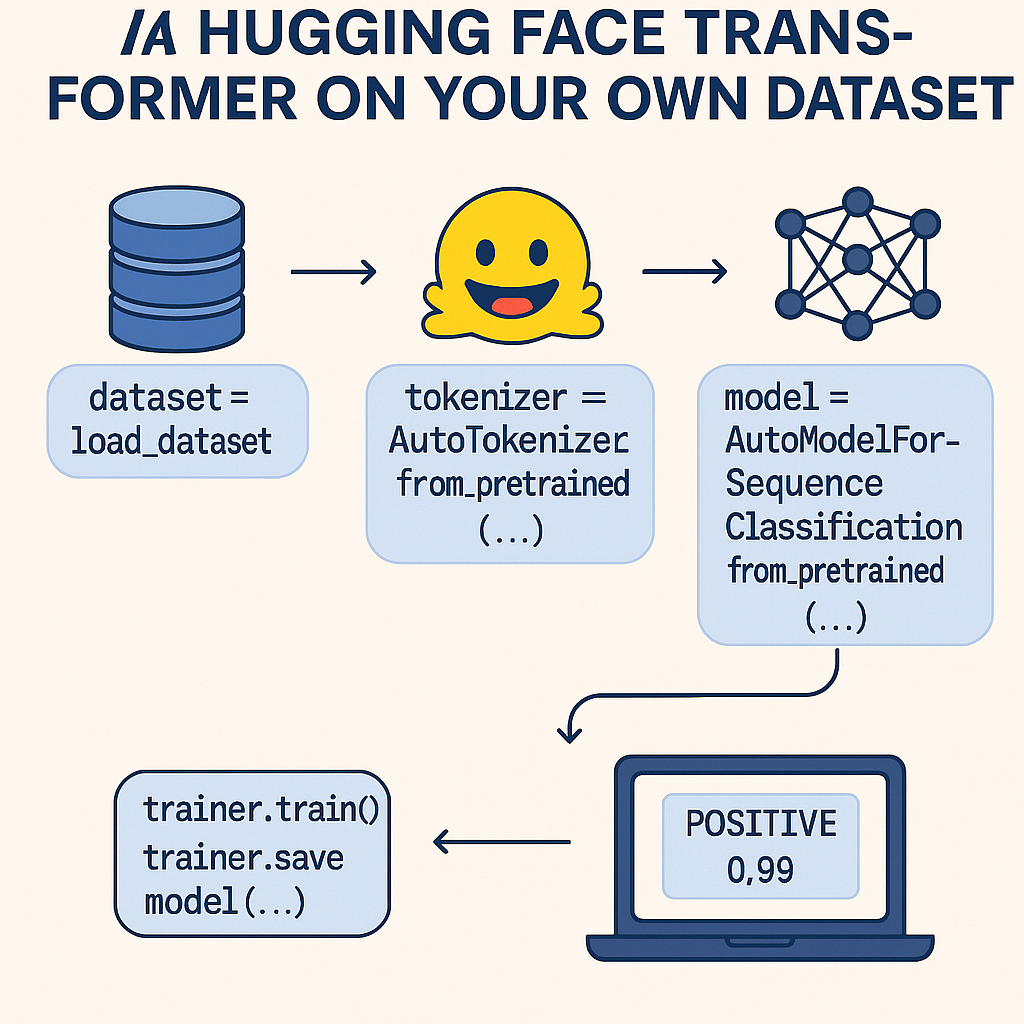
Table of Contents
Introduction
Fine-tuning a transformer model like BERT with Hugging Face empowers you to create domain-specific AI tools — from smart chatbots to precise classifiers tailored to your data. In this tutorial, we’ll walk through the practical steps of training your own Hugging Face model on a custom dataset.
Prerequisites
Before you begin, make sure you have the following:
- Python 3.7+
- Libraries:
transformers,datasets,scikit-learn - GPU (optional but recommended)
- Hugging Face account (for optional model sharing)
pip install transformers datasets scikit-learnStep 1: Load and Prepare Your Dataset
We’ll start by loading a sample dataset using Hugging Face’s datasets library. You can replace this with your CSV or JSON file if needed.
from datasets import load_dataset
from transformers import AutoTokenizer
dataset = load_dataset("imdb")
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
def tokenize_fn(example):
return tokenizer(example["text"], padding="max_length", truncation=True)
tokenized_dataset = dataset.map(tokenize_fn, batched=True)Step 2: Load a Pretrained Model
We use a BERT base model here, configured for binary classification.
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)Step 3: Set Up TrainingArguments and Trainer
Now we set the hyperparameters and initialize the trainer.
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=8,
evaluation_strategy="epoch",
save_strategy="epoch"
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["test"]
)Step 4: Train Your Model
Let’s kick off the training process.
trainer.train()Step 5: Evaluate and Save the Model
After training, we evaluate and save our custom model locally.
trainer.evaluate()
trainer.save_model("my-custom-bert")Step 6: Perform Inference with Your Fine-Tuned Model
Use Hugging Face’s pipeline for easy inference.
from transformers import pipeline
classifier = pipeline("text-classification", model="my-custom-bert")
print(classifier("This movie was fantastic!"))(Optional) Push Your Model to Hugging Face Hub
You can publish your model with:
transformers-cli login
trainer.push_to_hub("my-custom-bert")Conclusion
You’ve now successfully fine-tuned a Hugging Face Transformer on your dataset. This unlocks the ability to build powerful, domain-specific NLP tools with minimal effort. Try experimenting with different models like DistilBERT, RoBERTa, or even sequence-to-sequence models like T5 for tasks beyond classification.
Related Reading
- 🔥 Outstanding Training Custom Tokenizers With Hugging Face Transformers In Python: That Will Boost Your Transformer Expert!
- Expert Guide to How to Train a Custom AI LLM Model on Your Own Data That Will Revolutionize Your!
- 🔥 Master Nlp Fundamentals Transformers Context And Python: That Will 10x Your!
Enterprise AI Architecture
Want more enterprise AI architecture breakdowns?
Subscribe to SuperML.


