🌟 Gradient Boosting Machines Decoded: The Complete Guide That Will Make You a Machine Learning Expert!
Understand Gradient Boosting Machines (GBMs), their working principle, advantages, real-world applications, and Python examples in this easy-to-follow guide.

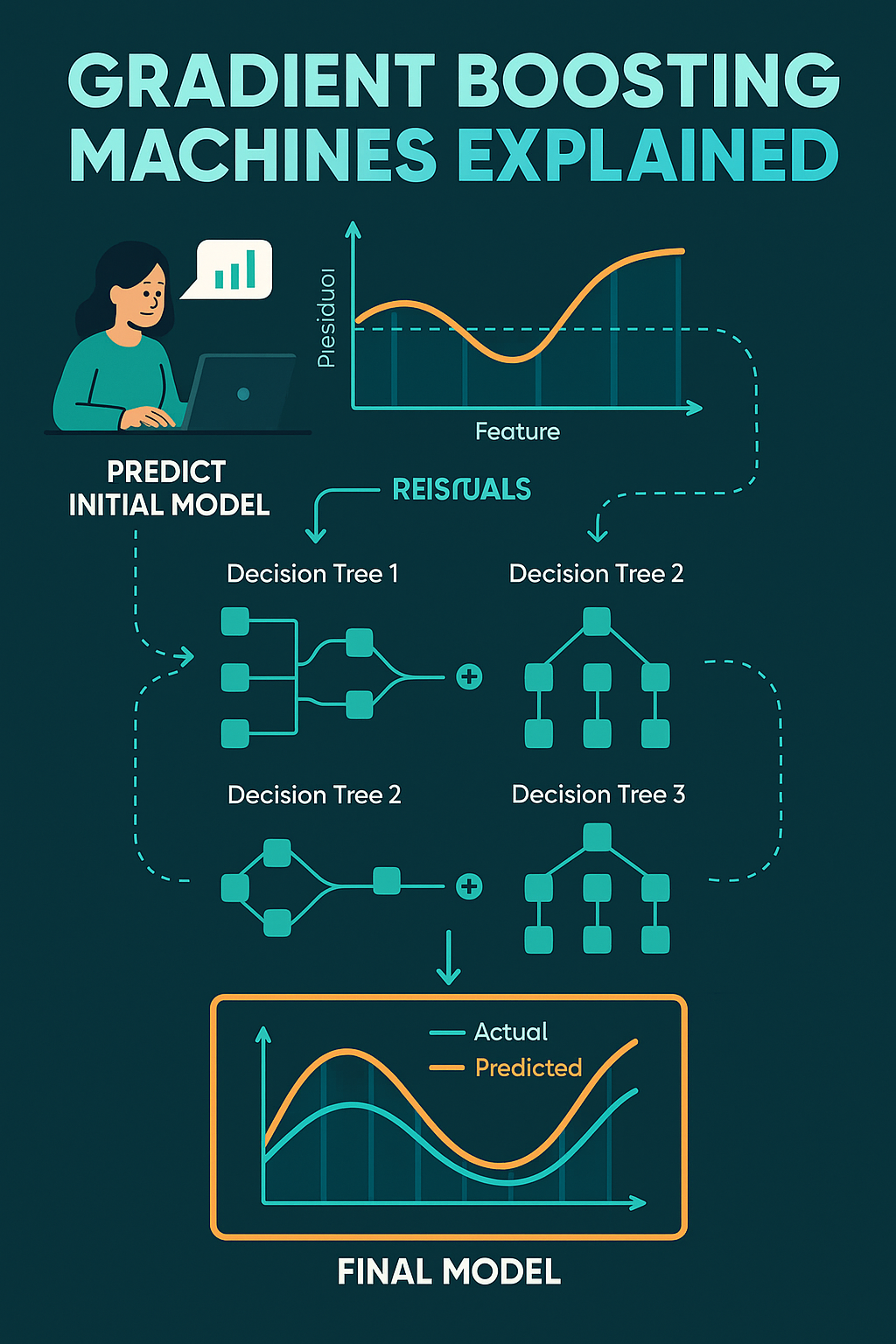
Table of Contents
Gradient Boosting Machines (GBMs) are one of the most powerful and widely-used algorithms in machine learning, especially for structured/tabular data. They form the backbone of many winning solutions in data science competitions like Kaggle and are widely adopted in production systems.
📘 What is Gradient Boosting?
Gradient Boosting is an ensemble learning technique that builds a strong model by combining multiple weak learners, typically decision trees. Unlike bagging methods like Random Forests, boosting builds models sequentially — each new tree tries to correct the mistakes made by the previous ones.
⚙️ How It Works
- Initialize a model with a constant prediction (like the mean of the target).
- Compute residuals — the difference between actual and predicted values.
- Fit a decision tree to these residuals.
- Update predictions by adding the tree’s output (scaled by a learning rate).
- Repeat steps 2–4 for a predefined number of iterations or until convergence.
Each step “boosts” the performance by correcting the previous errors.
🧠 Key Concepts
- Learning Rate (η): Controls how much each new tree affects the final prediction. Lower is more conservative (and needs more trees).
- Number of Estimators: How many trees to add.
- Tree Depth: Controls complexity and potential overfitting.
- Loss Function: Typically squared error for regression, log loss for classification.
🧪 Python Example with Scikit-learn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Generate synthetic data
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create model
model = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, max_depth=3)
model.fit(X_train, y_train)
# Predict and evaluate
y_pred = model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))Popular Implementations
- XGBoost: Highly efficient and accurate, often used in competitions.
- LightGBM: Faster and more memory-efficient; good for large datasets.
- CatBoost: Handles categorical data natively and avoids manual preprocessing.
✅ Advantages
- Handles both regression and classification.
- Robust to outliers and irrelevant features.
- Flexible with loss functions and model tuning.
⚠️ Disadvantages
- Sensitive to overfitting if not properly tuned.
- Training can be slower compared to simpler models.
- Less interpretable than linear models or single decision trees.
🌍 Real-World Applications
- Credit risk modeling
- Customer churn prediction
- Fraud detection
- Click-through rate prediction
- Medical diagnosis systems
🎯 Final Thoughts
Gradient Boosting Machines combine prediction power with flexibility, making them a go-to tool for many machine learning tasks. When tuned properly, they can achieve state-of-the-art performance across a variety of domains.
🧠 Want to master other ML algorithms? Explore more at superml.dev
Related Reading
- Supervised Learning: A Beginner-Friendly Guide with Examples Decoded: The Complete Guide That Will Make You an Expert!
- Unsupervised Learning: Discovering Hidden Patterns in Data Decoded: The Complete Guide That Will Make You an Expert!
- 🐍 Xgboost 20 With Python Decoded: The Complete Guide That Will Make You an Python Developer!
Enterprise AI Architecture
Want more enterprise AI architecture breakdowns?
Subscribe to SuperML.
