Explaining Frauds in Finance: A Real-World ML Example with Credit Card Authorization
A deep dive into real-time fraud detection with Credit Card Authorization using XGBoost, SHAP, and more
· SuperML.dev · agenticAI ·

In the world of digital finance, fraud detection has evolved from simple rule-based filters to real-time AI-powered defenses. This post dives into how we can build and explain a machine learning model to detect fraud in credit card authorization, using real Kaggle data, XGBoost, and SHAP.
🔍 Why Fraud Detection Matters
Fraudulent transactions in real-time systems (like credit card payments) can cause serious financial damage if not blocked instantly. The challenge: catching sophisticated patterns in milliseconds, without blocking good customers.
📊 Credit Card Fraud Detection Dataset
The dataset used in this post is a real-world anonymized dataset made available by researchers from ULB (Université Libre de Bruxelles) and hosted on Kaggle. It is commonly used for benchmarking fraud detection models.
🧾 Dataset Overview
- Total Records: 284,807 credit card transactions
- Fraud Cases: 492 (≈0.172% of total)
- Classes: Binary classification
0= Legitimate transaction1= Fraudulent transaction
🧠 Feature Description
Time: Seconds elapsed between first transaction and this one (used for behavior tracking)Amount: Transaction amount (used for scaling and detecting anomalies)V1toV28: Principal Components derived from a PCA transformation of original features (keeps privacy intact)Class: Target label (fraud or not)
Note: The original merchant, cardholder, location, and POS data have been anonymized, so advanced behavioral feature engineering is limited unless re-constructed via surrogate features (e.g., frequency, velocity, etc.)
📥 Download Method
We used the kagglehub library to programmatically download the latest version:
import kagglehub
import pandas as pd
path = kagglehub.dataset_download("mlg-ulb/creditcardfraud")
df = pd.read_csv(path + "/creditcard.csv")This makes the pipeline reproducible and portable for Colab, SageMaker, or local notebooks.
🧪 Feature Engineering Techniques & Importance
Feature engineering is a key part of building high-performing fraud detection systems, especially when working with anonymized or abstracted features like PCA components (V1 to V28). Here’s what we focused on:
🎯 Key Techniques Used
# Time since last transaction for a given PAN (if available)
df['txn_timestamp'] = pd.to_datetime(df['Time'], unit='s')
df = df.sort_values(['PAN', 'txn_timestamp'])
df['time_diff'] = df.groupby('PAN')['txn_timestamp'].diff().dt.total_seconds().fillna(0)
# Transaction amount relative to average (per PAN)
df['avg_txn_amount'] = df.groupby('PAN')['Amount'].transform('mean')
df['amount_ratio'] = df['Amount'] / (df['avg_txn_amount'] + 1e-6)
# Velocity feature: transactions per hour (rolling)
df['txn_count_hour'] = df.groupby('PAN')['txn_timestamp'].rolling('1H').count().reset_index(level=0, drop=True)
# First-time merchant flag (if Merchant ID available)
df['is_new_merchant'] = ~df.duplicated(subset=['PAN', 'Merchant_ID'])
# POS manual entry risk flag
df['is_manual_entry'] = (df['POS_Entry_Mode'] == 'manual').astype(int)🧠 Importance
These features help the model learn fraud-specific patterns, such as:
- Rapid fire transactions (velocity attack)
- Large, abnormal amounts
- Geo-anomalies (distance jumps)
- Risky entry modes (manual entries)
⚙️ Model Training and Evaluation
🔧 Hyperparameter Tuning with Optuna
To further improve model performance, we can use Optuna — a powerful hyperparameter optimization framework that integrates easily with XGBoost.
import optuna
import xgboost as xgb
from sklearn.model_selection import cross_val_score
from sklearn.metrics import roc_auc_score
# Objective function for tuning
def objective(trial):
params = {
'objective': 'binary:logistic',
'eval_metric': 'auc',
'scale_pos_weight': scale_weight,
'max_depth': trial.suggest_int('max_depth', 3, 10),
'eta': trial.suggest_float('eta', 0.01, 0.3),
'gamma': trial.suggest_float('gamma', 0, 5),
'subsample': trial.suggest_float('subsample', 0.5, 1.0),
'colsample_bytree': trial.suggest_float('colsample_bytree', 0.5, 1.0)
}
model = xgb.XGBClassifier(**params, use_label_encoder=False)
scores = cross_val_score(model, X_train, y_train, scoring='roc_auc', cv=3)
return scores.mean()
# Run study
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=30)
print("Best hyperparameters:", study.best_params)🧠 SHAP Summary Plot
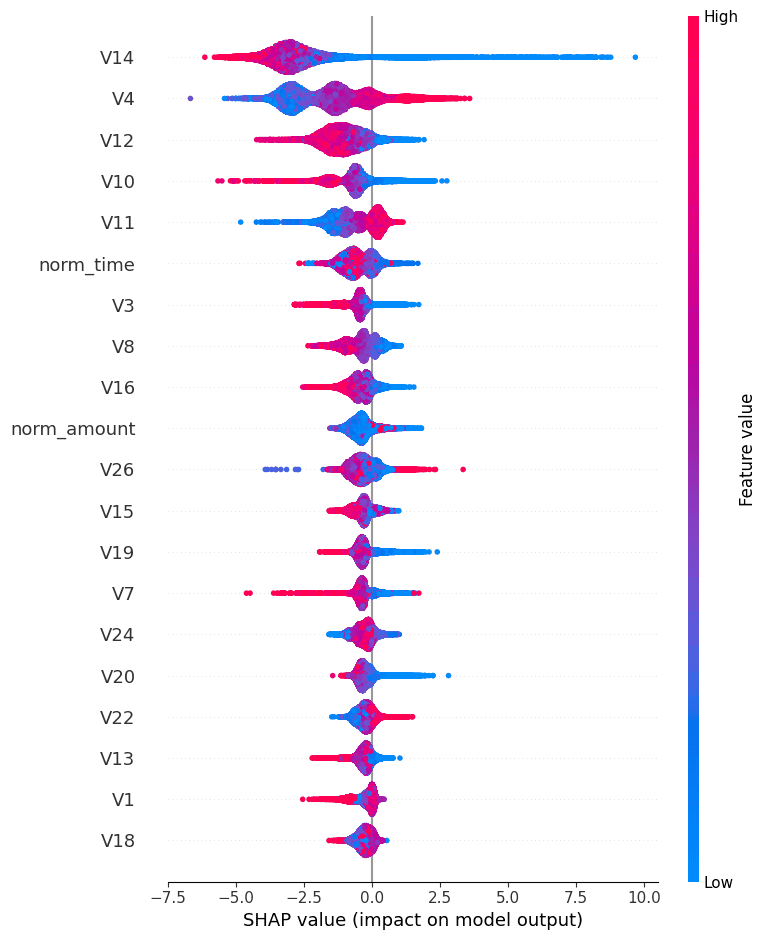
🔬 Single Transaction Explanation

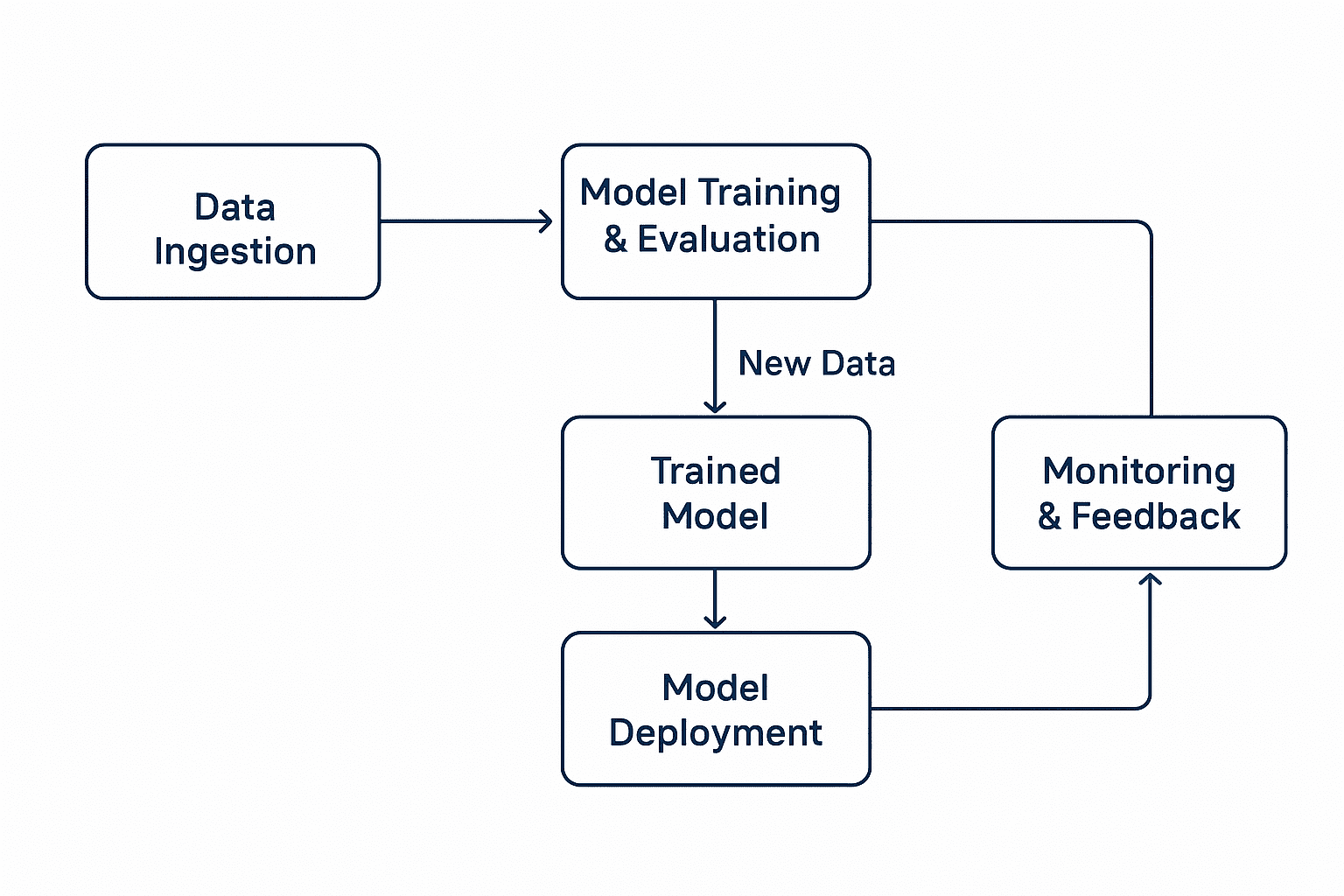
🧰 MLOps Architecture
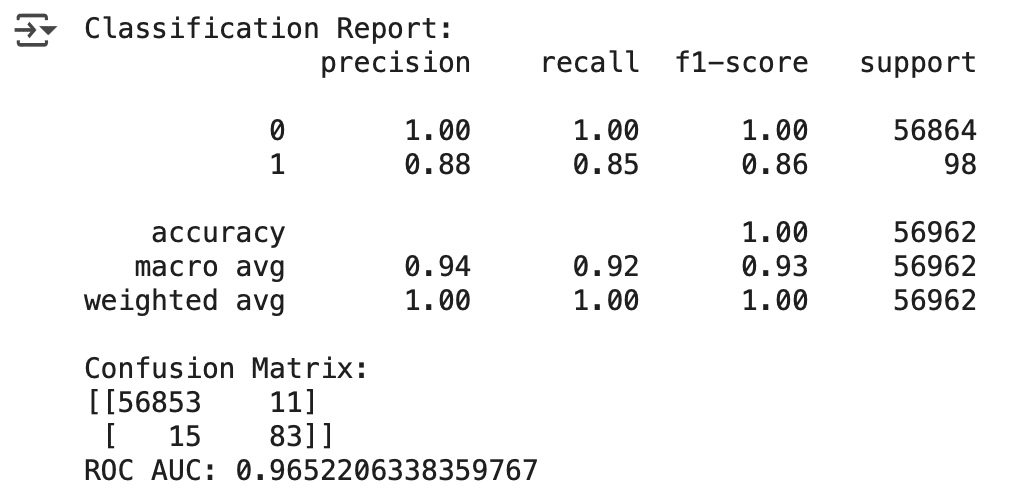
Model Performance
Fraud Detection Model Performance:
There is always space for improvement, Give your idea and suggestions on mode improvement Fraud Detection Model Performance
Give me your thoughts about these performance matrix.
Colab Notebook:
https://colab.research.google.com/drive/1tEo_JU8ao37mSKZdt3UjSC7CRM9WnzL7?usp=sharing
🔮 Coming Soon: Agentic AI for Financial Fraud Detection
In our next blog post, we’ll go beyond static models and build a full Agentic AI system that can:
- Orchestrate fraud detection using LangChain agents
- Query historical transaction data
- Explain and summarize suspicious behavior
- Trigger retraining or alerts using reasoning-driven logic
👉 Stay tuned as we turn this fraud detection model into an intelligent fraud-detecting agent.


{kind=link}