
Supervised vs Unsupervised Learning: Explained with Real-World Use Cases
by SuperML.dev,
Time spent: 0m 0s
As a data scientist, understanding the difference between supervised and unsupervised learning is crucial for solving practical business problems. This post compares both types in depth, showcases real-world examples, and includes code snippets and visuals.
Key Types of Machine Learning
Supervised Learning Types
- Classification – Predict discrete labels (e.g., spam vs. not spam, fraud vs. legitimate).
- Regression – Predict continuous values (e.g., house price, future sales).
Unsupervised Learning Types
- Clustering – Group similar items (e.g., customer segmentation).
- Association – Find rules among items (e.g., market basket analysis).
- Dimensionality Reduction – Simplify high-dimensional data (e.g., PCA, t-SNE).
Summary Table: Supervised vs Unsupervised Learning
| Aspect | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Data | Labeled | Unlabeled |
| Goal | Predict outcomes | Discover hidden patterns |
| Common Use Cases | Fraud detection, churn prediction | Customer segmentation, anomaly detection |
| Techniques | Classification, Regression | Clustering, Association, Dimensionality Reduction |
| Output Type | Specific target variable | Groupings or structure |
| Evaluation | Accuracy, precision, recall | Domain expert validation, cluster metrics |
Diagramatical view difference:
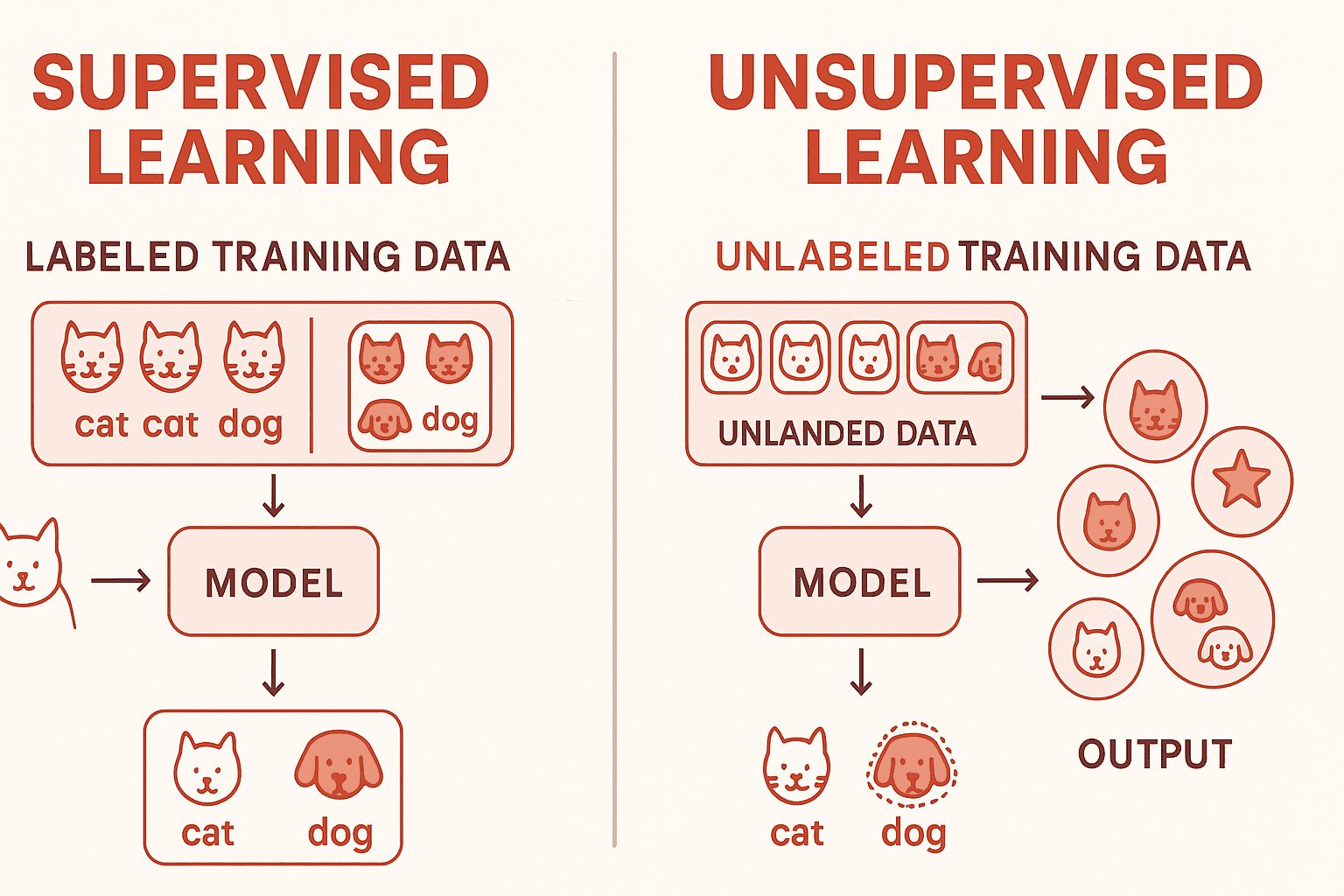
Supervised Learning in Practice
Supervised learning uses labeled datasets to train models to predict an outcome. There are two major subtypes:
- Classification: Predict a category label.
- Regression: Predict a numeric value.
Real-World Use Cases
- Fraud Detection: Label transactions as fraudulent or not.
- Customer Churn Prediction: Identify customers likely to leave.
- Sales Forecasting: Predict future revenue or product demand.
Sample Python Code (Classification)
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
X, y = iris.data, iris.target
model = DecisionTreeClassifier()
model.fit(X, y)
sample = [[5.1, 3.5, 1.4, 0.2]]
pred = model.predict(sample)
print("Predicted:", iris.target_names[pred][0])Unsupervised Learning in Practice
Unsupervised learning uses unlabeled data to uncover patterns.
Real-World Use Cases
- Customer Segmentation: Identify distinct customer groups.
- Anomaly Detection: Detect unusual patterns in data.
- Recommendation Systems: Use association rules for related item suggestions.
Sample Python Code (Clustering)
import numpy as np
from sklearn.cluster import KMeans
X = np.array([
[23, 40000],
[25, 42000],
[30, 45000],
[45, 80000],
[46, 82000],
[48, 85000]
])
model = KMeans(n_clusters=2)
labels = model.fit_predict(X)
print("Clusters:", labels)✅ When to Use What
- Use Supervised Learning when you have labeled data and want to make predictions.
- Use Unsupervised Learning to explore data, segment users, or detect anomalies when labels are not available.
📌 Conclusion
Both learning types offer distinct advantages. Supervised learning shines for prediction and automation, while unsupervised learning is invaluable for discovery and insight. Choose based on your goal—and combine when possible for best results.
Enjoyed this post? Join our community for more insights and discussions!
👉 Share this article with your friends and colleagues 👉 Follow us on